CN100416528C - 增强型通用输入/输出体系结构及在其中建立虚拟信道的有关方法 - Google Patents
增强型通用输入/输出体系结构及在其中建立虚拟信道的有关方法 Download PDFInfo
- Publication number
- CN100416528C CN100416528C CNB028193067A CN02819306A CN100416528C CN 100416528 C CN100416528 C CN 100416528C CN B028193067 A CNB028193067 A CN B028193067A CN 02819306 A CN02819306 A CN 02819306A CN 100416528 C CN100416528 C CN 100416528C
- Authority
- CN
- China
- Prior art keywords
- pseudo channel
- information
- channel
- general input
- pseudo
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Lifetime
Links
Images






Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F13/00—Interconnection of, or transfer of information or other signals between, memories, input/output devices or central processing units
- G06F13/10—Program control for peripheral devices
- G06F13/12—Program control for peripheral devices using hardware independent of the central processor, e.g. channel or peripheral processor
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F13/00—Interconnection of, or transfer of information or other signals between, memories, input/output devices or central processing units
- G06F13/10—Program control for peripheral devices
- G06F13/12—Program control for peripheral devices using hardware independent of the central processor, e.g. channel or peripheral processor
- G06F13/124—Program control for peripheral devices using hardware independent of the central processor, e.g. channel or peripheral processor where hardware is a sequential transfer control unit, e.g. microprocessor, peripheral processor or state-machine
Abstract
本发明提出了一种点到点互连和通信体系结构、协议及有关方法。
Description
优先权
本申请明确地要求了由Ajanovic等人于2001年8月26日递交的美国临时专利申请No.60/314,708,名为“A High-speed,Point-to-PointInterconnection and Communication Architecture,Protocol and RelatedMethods”(“高速、点到点互连和通信体系结构、协议及有关方法”)的优先权,该申请已被共同转让给本申请的受让人。
技术领域
本发明一般地涉及通用输入/输出总线体系结构,更具体地说,涉及高速、点到点的互连以及通信体系结构、协议和有关方法。
背景技术
计算装置,例如计算机系统、服务器、网络交换机和路由器、无线通信装置等,一般由多个不同的元件组成。这种元件通常包括处理器、微控制器和其它控制逻辑、存储器系统、输入和输出接口,等等。为了有助于这种元件间的通信,长期以来计算装置依赖于通用输入/输出(GIO)总线,用于使计算系统的这些不同元件彼此通信,以支持这种装置所提供的多种应用。
外围组件互连,或PCI总线体系结构可能是这种传统GIO总线体系结构中最普遍的一种。PCI总线标准(1998年12月18日发布的PeripheralComponent Interconnect(PCI)Local Bus Specification,Rev.2.2)定义了一种多接点式(multi-drop)、并行的总线体系结构,用于在计算装置内将芯片、扩展卡和处理器/存储器子系统以仲裁的方式互连起来。为各种目的,此处明确地包含了PCI局域总线标准的内容。尽管传统的PCI总线实现具有133Mbps的吞吐率(即,32位33MHz),但PCI 2.2标准允许每个管脚64位(bit)的并行连接,时钟高达133MHz,从而产生超过1Gbps的理论吞吐率。
在这方面,由这样的传统多接点式PCI总线体系结构提供的吞吐率到目前为止已经提供了足够的带宽来适应即使是最先进的计算装置(例如,多处理器服务器应用、网络装置等)的内部通信需要。然而,随着宽带因特网访问的广泛应用,处理能力的新近进展使处理速度超过了1GHz的阈值,诸如PCI总线体系结构之类的传统GIO体系结构已经变成这样的计算装置中的瓶颈。
通常与传统GIO体系结构联系在一起的另一个限制是,它们通常不能很好的适宜于操作/处理同步(或者说时间相关)数据流。这样的同步数据流的一个例子是多媒体数据流,该多媒体数据流需要同步传输机制来确保接收数据与使用数据同速,并且音频部分与视频部分同步。传统的GIO体系结构异步处理数据,或以带宽允许的随机时间间隔处理数据。这种同步数据的异步处理可能导致音频与视频的不重合,结果,某些同步多媒体内容供应商制定了使某些数据优先于其它数据的规则,例如使音频数据优先于视频数据,从而最终用户至少接收相对稳定的音频流(即,不被打断),使得他们可以欣赏或了解正在被流式播放的歌曲、故事等等。
发明内容
本发明的一个技术方案提供了一种用于在增强型通用输入/输出体系结构中建立虚拟信道的方法,该方法包括:接收用于通过通用输入/输出总线而传输到外部代理的信息;将所述通用输入/输出总线上总的可用带宽的一个子集动态分配为虚拟信道,以允许将所述信息传输到可通信地耦合的所述外部代理;以及至少部分地基于所接收的信息的内容,识别虚拟信道的类型,所述信息是通过所述虚拟信道而被允许传输的。
本发明的另一技术方案提供了一种用于在增强型通用输入/输出体系结构中建立虚拟信道的方法,该方法包括:接收用于通过通用输入/输出总线而传输到外部代理的信息;将所述通用输入/输出总线上总的可用带宽的一个子集动态分配为虚拟信道,以允许将所述信息传输到可通信地耦合的组件,其中所述虚拟信道是在所述通用输入/输出总线上建立的多达多条虚拟信道中的一条,其中独立地管理所述虚拟信道中每条信道的状态。
本发明的另一技术方案提供了一种计算设备,该计算设备包括:通用输入/输出总线;和两个或多个组件,其中每个组件都与所述通用输入/输出总线可通信地耦合,其中所述组件中的一个或多个包括增强型通用输入/输出接口,用于建立虚拟信道,所述虚拟信道动态地共享所述通用输入/输出总线的物理资源,以允许在所述两个或多个组件之间传送信息,所述增强型通用输入/输出接口包括:事务层,用于从组件中的一个或多个处理代理接收信息,并建立一条或多条虚拟信道,用所述虚拟信道来将信息从所述一个或多个处理代理传送给一个或多个外部代理。
附图说明
在附图中,示例性而不一定限制性地对本发明进行了图示,其中相似的标号指示相似的元件。
图1是根据本发明教导的电子装置的方框图,该电子装置包括本发明的一个或多个方面以便于该装置的一个或多个组成元件之间的通信;
图2示出了根据本发明一个示例性实施例的示例性通信栈,该通信栈由电子装置的一个或多个元件使用,以便于这些元件之间的通信;
图3是根据本发明教导,示出了示例性事务(transaction)描述符的示图;
图4示出了根据本发明一个方面的示例性通信链路,该通信链路包括一个或多个虚拟信道以便于电子设备的一个或多个元件之间的通信;
图5是根据本发明一个示例性实施例,用于实现本发明一个或多个方面的示例性通信代理的方框图;
图6是本发明的事务层中使用的各种分组头部格式的方框图;
图7是根据本发明示例性实施例的示例性存储器体系结构的方框图,该存储器体系结构被用于辅助本发明的一个或多个方面;
图8是根据本发明一个方面的示例性链路状态机图的状态图;以及
图9是一种可访问介质的方框图,该介质包括当由电子设备访问时实现本发明一个或多个方面的内容。
图10是根据本发明一个方面,在通用输入/输出总线体系结构中建立虚拟信道的示例性方法的流程图。
具体实施方式
本发明一般地涉及创新的点到点互连体系结构、通信协议及有关方法,用于提供用在电子装置中可扩展/可扩充(scalable/extensible)的通用输入/输出(I/O)通信平台。在这方面,介绍了创新的增强型通用输入/输出(EGIO)互连体系结构、和相关的EGIO通信协议。根据一个示例性实施例,EGIO体系结构的不同元件包括主桥(host bridge)、交换器(switch)或端点(end-point)中的一个或多个,每个元件至少包含EGIO特征的一个子集以支持这些元件之间的EGIO通信。
使用(多条)串行通信信道来执行这些元件的EGIO设备之间的通信,所述串行通信信道使用创新EGIO通信协议,所述协议如下面将要详细介绍的那样支持一个或多个创新特征,所述创新特征包括但不限于虚拟通信信道、基于尾部(tailer)的差错转发(error forwarding)、对老式的基于PCI的设备的支持、多种请求响应类型、流控制和/或数据完整性管理功能。根据本发明的一个方面,通过引入EGIO通信协议栈,在计算装置的每个元件中都支持所述通信协议,该栈包括物理层、数据链路层和事务层。
根据另一种实现,引入了通信代理(communications agent),其包含EGIO引擎,该引擎至少包括上述特征的一个子集。从下面的讨论中将会清楚,所述通信代理可以很好地被电子设备的老式元件所使用,以将本发明的通信协议要求引入到其它非EGIO互连装置体系结构中。根据上文和下文的描述,本领域技术人员将会意识到,可以将本发明的一个或多个元件包含在硬件、软件、传播信号或其结合中。
在本说明书各处提及的“一个实施例”或“实施例”指的是,所描述的与该实施例有关的具体特征、结构或特性被包括在本发明的至少一个实施例中。因此,在本说明书多个位置出现的短语“在一个实施例中”或“在实施例中”不一定都指同一实施例。此外,所述具体特征、结构或特性可以适当的方式结合在一个或多个实施例中。
术语
在深入讨论创新的EGIO互连体系结构和通信协议的细节之前,引入将在该详细描述中使用的词汇表元素是很有帮助的:
·通告(Advertise):在EGIO流控制的上下文中使用,是指接收器通过使用EGIO协议的流控制更新消息来发送有关它的流控制信用量(credit)可用性的信息的动作;
·完成器(Completer):请求所指向的逻辑设备;
·完成器ID:完成器的总线标识符(例如,号码)、设备标识符和功能标识符中的一个或多个的组合,其唯一标识了请求的完成器;
·完成(completion):用于终止或部分终止一个序列的分组被称为完成。根据一个示例性实现,完成对应于在前请求,并且在某些情况下含有数据;
·配置空间:EGIO体系结构中的四个地址空间中的一个。具有配置空间地址的分组被用于对设备进行配置;
·组件:物理设备(即,在单个封装之中);
·数据链路层:EGIO体系结构的中间层,位于事务层(上层)和物理层(下层)之间;
·数据链路层分组(DLLP):数据链路层分组是在数据链路层产生并使用的分组,用于支持链路管理功能;
·下行流(downstream):指的是元件的相对位置或离开主桥的信息流;
·端点:具有00h类型配置空间头部的EGIO设备;
·流控制:用于将来自接收器的接收缓冲器信息发送到发送器,以防止接收缓冲器溢出,并使发送器装置可以服从排序规则;
·流控制分组(FCP):事务层分组(TLP),用于将来自一个组件中的事务层的流控制信息发送到另一个组件中的事务层;
·功能:多功能设备的一个独立部分,在配置空间中由唯一的功能标识符(例如,功能号码)标识;
·层次结构(Hierarchy):定义了在EGIO体系结构中实现的I/O互连拓扑结构。层次结构由对应于最靠近枚举设备(enumerating device)(例如,主CPU)的链路的单一主桥来表征;
·层次结构域:EGIO层次结构被主桥分成多个段,所述主桥产生多于一个EGIO接口,其中这些段被称为层次结构域;
·主桥:将主CPU复合体(complex)连接到一个或多个EGIO链路;
·IO空间:EGIO体系结构的四个地址空间中的一个;
·管线(Lane):物理链路的一组差分信号对,一对用于发送,一对用于接收。N接口(by-N interface)由N条管线组成;
·链路:两个组件之间的双单工(dual-simplex)通信路径;两个端口(一个发送,一个接收)及其(多条)互连管线的集合;
·逻辑总线:在配置空间中具有相同总线号码的一系列设备之间的逻辑连接;
·逻辑设备:EGIO体系结构的元件,其在配置空间中对应于唯一的设备标识符;
·存储器空间:EGIO体系结构的四个地址空间中的一个;
·消息:具有消息空间类型的分组;
·消息空间:EGIO体系结构的四个地址空间中的一个。如PCI中定义的专门周期作为消息空间的子集而被包括在其中,并且因此提供了(多个)与老式设备的接口;
·(多个)老式软件模型:初始化、发现、配置以及使用老式设备所需的(多个)软件模型(例如,在例如EGIO至老式桥中所包含的PCI软件模型有助于与老式设备的交互);
·物理层:EGIO体系结构层,其直接面对两个组件之间的通信介质;
·端口:与组件相关联的接口,在该组件和EGIO链路之间;
·接收器:通过链路接收分组信息的组件是接收器(有时称为目标);
·请求:用于发起序列的分组被称为请求。请求包括一些操代码,并且在某些情况下,包括地址和长度、数据或其它信息;
·请求器(requester):首先将序列引入到EGIO域的逻辑设备;
·请求器ID:请求器的总线标识符(例如,总线号码)、设备标识符和功能标识符中的一个或多个的组合,其唯一地标识请求器。在大多数情况下,EGIO桥或交换器将请求从一个接口转发到另一个接口而不修改请求器ID。来自除EGIO总线之外的总线的桥通常应当存储请求器ID,以在为该请求产生一个完成时使用。
·序列:单个请求,以及与请求器执行单个逻辑传送相关联的零个或更多个完成;
·序列ID:请求器ID和标记(Tag)中一个或多个的组合,其中所述组合唯一地标识作为公共序列一部分的请求和完成;
·分裂事务(split transaction):含有初始事务(分裂请求)的单个逻辑传送,目标(完成器或桥)以一个分裂响应来终止该事务,随后由完成器(或桥)发起一个或多个事务(分裂完成),以将读取数据(如果读取)或完成消息发送回请求器;
·符号(symbol):作为8位/10位编码的结果而产生的10位数值;
·符号时间:在管线上放置符号所需的时间段;
·标记:由请求器分配到给定序列以将其与其它序列区分开的号码,它是序列ID的一部分;
·事务层分组(TLP):TLP是在事务层中产生以运送请求或完成的分组;
·事务层:EGIO体系结构的最外层(最上层),其在事务级别进行操作(例如,读取、写入等等);
·事务描述符:分组头部的元素,与地址、长度和类型一起描述事务的属性。
示例性电子装置
图1是根据本发明教导的简化电子装置100的方框图,该电子装置包括增强型通用输入/输出(EGIO)总线体系结构、协议及有关方法。根据图1所示的例子,电子装置100被示出为包含多个电子元件,包括(多个)处理器102、主桥104、交换器108以及端点110中的一个或多个,每个元件都如图所示进行耦合。根据本发明的教导,至少主桥104、(多个)交换器108以及端点110被赋予了EGIO通信接口106的一个或多个示例,以有助于本发明的一个或多个方面。
如图所示,元件102、104、108和110中的每一个都经由EGIO接口106通过通信链路112可通信地耦合到至少一个其它元件,其中通信链路112支持一条或多条EGIO通信信道。如上面所介绍的,希望用电子装置100代表多种传统和非传统计算系统、服务器、网络交换器、网络路由器、无线通信用户单元、无线通信电话基础设施元件、个人数字助理、机顶盒或任何电子装置中的任何一个或多个,所述任何电子装置将从通过结合这里描述的EGIO互连体系结构、通信协议或相关方法的至少一个子集而产生的通信资源中获益。
根据图1所示的示例性实现,电子装置100具有一个或多个处理器102。这里所使用的(多个)处理器102控制电子装置100的功能性能力的一个或多个方面。在这个方面,(多个)处理器102可以代表多种控制逻辑中的任何一个,所述控制逻辑包括但不限于微处理器、可编程逻辑组件(PLD)、可编程逻辑阵列(PLA)、专用集成电路(ASIC)、微控制器等中的一个或多个。
主桥104在电子装置EGIO体系结构的处理器102和/或处理器/存储器复合体,以及一个或多个其它元件108、110之间提供通信接口,并且在这方面,其作为EGIO体系结构层次结构的根(root)。这里所使用的主桥104指的是最靠近于主控制器、存储器控制中心、IO控制中心、上述的任何组合或芯片组/CPU元件的某种组合(即,处于计算系统环境中)的EGIO层次结构的逻辑实体。在这方面,尽管在图1中被示出为单个单元,但主桥104可以被认为是可具有多个物理组件的单个逻辑实体。根据图1所示的示例性实现,主桥104组装有一个或多个EGIO接口106以便于与其它外围设备进行通信,所述外围设备例如是(多个)交换器108、(多个)端点110以及(多个)老式桥114或116,尽管没有具体示出老式桥114或116。根据一个实现,每个EGIO接口106代表不同的EGIO层次结构域。在此方面,图1所示的实现表示了具有三(3)个层次结构域的主桥104。应当注意到,尽管被示出为包括多个单独EGIO接口106,但是可以预期其它的实施例,其中单个接口106具有多个端口以适应和多个设备进行通信。
根据本发明的教导,交换器108具有至少一个上行流(upstream)端口(即、导向主桥104)和至少一个下行流端口。根据一个实现,交换器108将最靠近主桥的一个端口(即,接口的一个端口或接口106自身)作为上行流端口,而所有其它的端口是下行流端口。根据一个实现,交换器108对于配置软件(例如,老式配置软件)表现为PCI到PCI桥,并且使用PCI桥机制来对事务进行路由。
在交换器108的上下文中,对等(peer-to-peer)事务被定义为这样的事务,其中的接收端口和发送端口都是下行流端口。根据一个实现,交换器108支持对所有类型的事务层分组进行路由,但除了那些与从任何端口到任何其它端口的锁定事务序列相关联的事务层分组(TLP)之外。在这方面,所有广播消息一般都会从交换器108上的接收端口被路由到它的所有其它端口。不能被路由到端口的事务层分组一般会被交换器108确定为不支持的TLP。当将事务层分组(TLP)从接收端口传送到发送端口时,交换机108一般不修改它们,除非需要进行修改以适应发送端口(例如,耦合至老式桥114、116的发送端口)的不同协议需求。
应当意识到,交换器108代表其它设备工作,并且在这方面,它不能预先知道流量类型和模式。根据下面将要详细讨论的一个实现,本发明的流控制和数据完整性方面以每个链路(per-link)为基础而实现,而不是以端到端(end-to-end)为基础实现。因此,根据这样的实现,交换器108参与用于流控制和数据完整性的协议。为了参与流控制,交换器108为每个端口维持单独的流控制以提高交换器108的性能特性。类似地,交换器108通过使用TLP检错机制检查进入交换器的每个TLP而以每个链路为基础来支持数据完整性处理,这在下面将详细描述。根据一个实现,允许交换器108的下行流端口形成新的EGIO层次结构域。
继续参考图1,端点110被定义为具有00hex(十六进制00)(00h)类型配置空间头部的任何设备。端点设备110可以是EGIO语义事务的请求器或完成器,可以代表它自身或是代表截然不同的非EGIO设备。这样的端点110示例包括但不限于EGIO兼容(EGIO compliant)图形设备、EGIO兼容存储器控制器以及/或者实现了EGIO和诸如通用串行总线(USB)、以太网等某些其它接口之间的连接的设备。与下文详细讨论的老式桥114、116不同,担当非EGIO兼容设备的接口的端点110不会为这些非EGIO兼容设备提供完全软件支持。虽然认为将主处理器复合体102连接到EGIO体系结构的设备是主桥104,但是它可以是与位于EGIO体系结构中的其它端点110类型相同的设备,它们只是通过其相对于处理器复合体102的位置来加以区分。
根据本发明的教导,端点110可以被概括为下列三个类别的一个或多个:(1)老式与EGIO兼容端点,(2)老式端点,以及(3)EGIO兼容端点,每个在EGIO体系结构中具有不同的操作规则。
如上所述,EGIO兼容端点110与老式端点(例如,118、120)的不同之处在于,EGIO端点110具有00h类型配置空间头部。这些端点(110、118和120)中的每个都作为完成器而支持配置请求。这些端点被允许产生配置请求,并且可以被分类为老式端点或EGIO兼容端点,但是该分类需要遵守以下的其它规则。
老式端点(例如,118、120)被允许作为完成器来支持IO请求并被允许产生IO请求。如果老式端点(118、120)的老式软件支持需求需要的话,就允许其作为完成者而产生锁定语义(lock semantics)。老式端点一般不发出锁定请求。
EGIO兼容端点110一般不作为完成器来支持IO请求并且不产生IO请求。EGIO端点110不作为完成器来支持锁定请求,并且不作为请求器来产生锁定请求。
EGIO至老式桥114、116是专用端点110,其包括用于老式设备(118、120)的基本软件支持例如完全软件支持,其中所述桥将所述老式设备连接到EGIO体系结构。在这方面,老式桥114、116一般具有一个上行流端口(但也可以具有多个),并具有多个下行流端口(但也可以只有一个)。根据老式软件模型来支持锁定请求。老式桥114、116的上行流端口应当以每个链路为基础来支持流控制并且遵守EGIO体系结构的流控制和数据完整性规则,这在下文中将详细介绍。
这里所使用的通信链路112意在代表多种通信介质中的任何一个,所述多种通信介质包括但不局限于铜线、光纤、(多条)无线通信信道、红外通信链路等等。根据一个示例性实现,EGIO链路112是差分串行线路对,一对中的每个都支持发送和接收通信,从而提供了对全双工通信能力的支持。根据一个实现,链路提供具有初始(基本)操作频率为2.5Ghz的可扩展串行时钟频率。每个方向的接口宽度可依x1、x2、x4、x8、x12、x16、x32物理管线而扩展。如上所述以及下面将要详细介绍的,EGIO链路112可以支持设备间的多条虚拟信道,从而使用一条或多条虚拟信道在这些设备之间提供对同步流量的不间断通信的支持,所述多条虚拟信道例如是一条音频信道和一条视频信道。
示例性EGIO接口体系结构
图2示出了根据本发明一个示例性实施例的示例性EGIO接口106体系结构,其由电子装置的一个或多个元件使用,以便于这些元件之间的通信。根据图2所示的示例性实现,EGIO接口106可以表示为包括了事务层202、数据链路层204和物理层206的通信协议栈。如图所示,物理链路层接口被示出为包括逻辑子块210和物理子块,其中每个都将在下面进行更详细的讨论。
事务层
根据本发明的教导,事务层202提供EGIO体系结构和设备核心之间的接口。在这方面,事务层202的主要职责是为主设备(或代理)中的一个或多个逻辑设备装配和拆解分组(即,事务层分组或TLP)。
地址空间、事务类型和用途
事务形成了在发起代理和目标代理之间的信息传送的基础。根据一个示例性实施例,在创新的EGIO体系结构中定义了四个地址空间,包括例如配置地址空间、存储器地址空间、输入/输出地址空间以及消息地址空间,每个都具有自己唯一的预期用途(例如见图7,下面进行了详细的说明)。
存储器空间(706)事务包括读取请求和写入请求中的一个或多个,以将数据发送到存储器映射位置或从该位置取出数据。存储器空间事务可以使用两种不同的地址格式,例如短地址格式(例如,32位地址)或长地址格式(例如,64位的长度)。根据一个示例性实施例,EGIO体系结构使用锁定协议语义(即,代理可以锁定对所修改的存储器空间的访问)来提供传统的读取、修改和写入序列。更具体地说,根据特定设备规则(桥、交换器、端点、老式桥),允许实现对下行流锁定的支持。如上所述,支持这种锁定语义,以支持老式设备。
IO空间(704)事务用于访问IO地址空间(例如,16位IO地址空间)中的输入/输出映射存储器寄存器。诸如英特尔体系结构(IntelArchitecture)处理器以及其它处理器的某些处理器102通过处理器的指令集而包括IO空间定义。因此,IO空间事务包括读取请求和写入请求以将数据传送至IO映射位置或从该位置取出数据。
配置空间(702)事务用于访问EGIO设备的配置空间。配置空间的事务包括读取请求和写入请求。由于如此多的传统处理器一般不含有本地配置空间,所以通过一种机制来映射该空间,所述机制即是与传统PCI配置空间访问机制(例如,使用基于CFC/CFC8的PCI配置机制#1)相兼容的软件。或者,也可以使用存储器别名机制来访问配置空间。
消息空间(708)事务(或简称为消息)被定义为支持通过(多个)接口106而在EGIO代理之间进行带内通信。由于传统的处理器不包括对本地消息空间的支持,所以这是通过EGIO代理在接口106中实现的。根据一个示例性实现,诸如中断和电源管理请求的传统“边带(side-band)”信号作为消息而被实现,以减少所需的用来支持这些老式信号的引脚数目。一些处理器以及PCI总线包括“专用周期”(special cycles)的概念,其也被映射到EGIO接口106中的消息。根据一个实施例,消息通常分为两类:标准消息和厂商定义消息。
根据所图示的示例性实施例,标准消息包括通用消息组和系统管理消息组。通用消息可以是单一目的地消息或广播/组播消息。系统管理消息组可以包括中断控制消息、电源管理消息、排序控制原语(primitive)和差错信令中的一个或多个,它们的例子将在下文中介绍。
根据一个示例性实现,通用消息包括支持锁定事务的消息。根据该示例性实现,引入了UNLOCK(解锁)消息,其中交换器(例如,108)一般会通过可能参与锁定事务的任何端口来转发UNLOCK消息。在没有被锁定时接收到UNLOCK消息的端点设备(例如,110、118、120)将忽略该消息。否则,将在接收到UNLOCK消息之后将被锁定的设备解锁。
根据一个示例性实现,系统管理消息组包括用于排序和/或同步消息的专用消息。一个这样的消息是FENCE(防护)消息,用于在由EGIO体系结构的接收元件产生的事务上施加严格的排序规则。根据一个实现,只有网络元件的一个所选子集,例如端点,对该FENCE消息作出反应。除前述的内容以外,这里还预见了例如通过使用下文讨论的尾部差错转发,来产生指示可校正差错、不可校正差错和致命差错的消息。
根据上文所介绍的本发明的一个方面,系统管理消息组使用带内消息提供中断信令。根据一个实现,引入了ASSERT_INTx/DEASSERT_INTx消息对,其中断言(assert)中断消息的发布通过主桥104被发送到处理器复合体。根据所图示的示例性实现,ASSERT_INTx/DEASSERT_INTx消息对的使用规则反映了PCI规范中的PCI INTx#信号的消息的使用规则,如上所述。对于来自任何一个设备的Assert_INTx的每次发送,通常都有对应的Deassert_INTx的发送。对于特定‘x’(A、B、C或D),一般在发送Deassert_INTx之前只发送一次Assert_INTx。交换器一般会将Assert_INTx/Deassart_INTx消息路由到主桥104,其中主桥一般会跟踪Assert_INTx/Deassart_INTx消息以产生虚拟中断信号,并且将这些信号映射到系统中断资源。
除了通用和系统管理消息组之外,EGIO体系结构建立了标准框架,其中核心逻辑(例如芯片组)厂商可以定义它们自己的厂商定义消息以迎合它们的平台的特定操作需求。该框架是通过公共消息头部而建立的,在所述头部中厂商定义消息的编码被规定为“预留”。
事务描述符
事务描述符是用于将事务信息从起点运送到服务点并送回的机制。它提供可扩展装置,用于提供可以支持新类型的新兴应用的通用互连解决方案。在这方面,事务描述符支持系统中的事务的标识、缺省事务排序的修改,以及使用虚拟信道ID机制将事务与虚拟信道相关联。参考图3,示出了事务描述符的示图。
参考图3,根据本发明的教导示出了包括示例性事务描述符的数据报的示图。根据本发明的教导,所示出的事务描述符300包括全局标识符字段302、属性字段304和虚拟信道标识符字段306。在所图示的示例性实现中,全局标识符字段302被示出为包括本地事务标识符字段308和源标识符字段310。
·全局事务标识符302
这里所使用的全局事务标识符对所有待处理的请求都是唯一的。根据图3所示的示例性实现,全局事务标识符302由两个子字段组成:本地事务标识符字段308和源标识符字段310。根据一个实现,本地事务标识符字段308是由每个请求器产生的8位字段,并且对于需要该请求器的完成的所有待处理请求它是唯一的。源标识符唯一地标识EGIO层次结构中的EGIO代理。因此,本地事务标识符字段和源ID一起提供了在层次结构域中的事务的全局标识。
根据一个实现,本地事务标识符308允许来自单个请求源的请求/完成乱序(遵守下面详细讨论的排序规则)操作。例如,读取请求源可以产生读取A1和A2。处理这些读取请求的目的地代理会首先返回请求A2事务ID的完成,并且随后返回A1的完成。在完成分组头部中,本地事务ID信息将标识哪个事务将被完成。这种机制对于使用分布式存储器系统的装置尤为重要,因为它可以更有效的方式来操作读取请求。应当注意,对这种乱序读取完成的支持假定了发布读取请求的设备将确保完成的缓冲器空间的预先分配。如上所述,只要EGIO交换机108不是端点(即,仅仅传送完成请求到适当的端点),它们就不需要预留缓冲器空间。
单个读取请求可以导致多个完成。属于单个读取请求的完成可以相互乱序地返回。这通过在完成分组头部(即,完成头部)中提供与部分完成相对应的初始请求的地址偏移来支持。
根据一个示例性实现,源标识符字段310包含对每个逻辑EGIO设备唯一的一个16位值。应当注意单个EGIO设备可以包括多个逻辑设备。在系统配置期间以对标准PCI总线枚举机制透明的方式分配源ID值。EGIO设备使用例如在对那些设备的初始配置访问期间可用的总线号码信息以及用于表示例如设备号码和流号码的内部可用信息,在内部自动地建立源ID。根据一个实现,该总线号码信息是在EGIO配置周期期间使用与PCI配置所使用的相类似的机制而产生的。根据一个实现,总线号码由PCI初始化机制分配并由每个设备捕获。在热插拔和热交换设备的情况下,这些设备将需要在每个配置周期访问上重新捕获该总线号码信息,以能够对SHPC(标准热插拔控制器)软件栈透明。
根据EGIO体系结构的一个实现,物理组件可以包含一个或多个逻辑设备(或代理)。每个逻辑设备被设计成对指定到其特定设备号码的配置周期进行响应,即,在逻辑设备中加入了设备号码的概念。根据一个实现,在单个物理组件中允许多达十六个逻辑设备。每个这样的逻辑设备可以包括一个或多个流化(streaming)引擎,例如多达16个。因此,单个物理组件可以包括多达256个流化引擎。
由不同源标识符标记的事务属于不同的逻辑EGIO输入/输出(IO)源,并且从而从排序的方面来看可以相互完全独立地操作这些事务。对于三方对等事务的情况,如果需要,可以使用防护排序控制原语来强制排序。
这里所使用的事务描述符300的全局事务标识符字段302遵守下列规则的至少一个子集:
(a)每个需要完成的请求用全局事务ID(GTID)来标记;
(b)由代理发起的所有待处理的需要完成的请求一般应当分配唯一的GTID;
(c)不需要完成的请求不使用GTID的本地事务ID字段308,并且本地事务ID字段被认为是预留的;
(d)目标不需要以任何方式来修改请求GTID,而只是为所有与请求相关联的完成而在完成分组的头部中回应它,其中发起者使用GTID将(多个)完成与原始请求相匹配。
·属性字段304
这里所使用的属性字段304指明了事务的特性和关系。在这方面,属性字段304被用于提供允许修改事务缺省操作的额外信息。这些修改可以应用于在系统中操作事务的不同方面,例如排序、硬件一致性(coherency)管理(例如探听(snoop)属性)和优先级。一种示例性格式以子字段312-318来表示属性字段304。
如图所示,属性字段304包括优先级子字段312。优先级子字段可以由发起者修改来为事务分配优先级。例如在一个示例性实现中,事务或代理的服务的等级或服务质量特性可以在优先级子字段312中实现,从而影响其它系统元件进行的处理。
预留属性字段314为将来或厂商定义用途而被预留。通过使用预留属性字段可以实现使用优先级或安全属性的可能的用途模型。
排序属性字段316被用于提供用来传达排序类型的可选信息,所述信息可以修改同一排序平面(ordering plane)(其中排序平面包括由具有对应的源ID的IO设备和主处理器(102)发起的流量)内的缺省排序规则。根据一个示例性实现,排序属性‘0’表示将应用缺省的排序规则,而排序规则‘1’表示松散(relaxed)排序,其中在同一方向上写入可以超过写入,并且在同一方向上读取完成可以超过写入。使用松散排序语义的设备主要用于以缺省排序来为读取/写入状态信息移动数据和事务。
探听属性字段318被用于提供用来传达缓存一致性管理的类型的可选信息,所述信息可以修改同一排序平面内的缺省缓存一致性管理规则,其中排序平面包括由具有对应的源ID的IO设备和主处理器102发起的流量。根据一个示例性实现,探听属性字段318值‘0’对应于缺省缓存一致性管理方案,其中探听事务以增强硬件级别的缓存一致性。另一方面,探听属性字段318中的值‘1’中止缺省缓存一致性管理方案,并且不探听事务。相反,所访问的数据或者是非可缓存的(non-cacheable),或者其一致性由软件来管理。
·虚拟信道ID字段306
这里所使用的虚拟信道ID字段306标识与事务相关联的独立虚拟信道。根据一个实施例,虚拟信道标识符(VCID)是4位字段,其允许以每个事务为基础来标识多达16个虚拟信道(VC)。下面的表I中提供了VCID定义的一个示例:
| VCID | VC名字 | 用途模型 |
| 0000 | 缺省信道 | 通用流量 |
| 0001 | 等时信道(isochronous channel) | 本信道用于运送具有下列需求的IO流量:(a)不被探听以考虑确定性服务定时的IO流量;以及(b)使用X/T协定(其中X=数据量、T=时间)来控 |
| 制服务质量 | ||
| 0010-1111 | 预留 | 将来使用 |
表I:虚拟信道ID编码
虚拟信道
根据本发明的一个方面,EGIO接口106的事务层202支持在EGIO通信链路112的带宽内建立一条或多条虚拟信道。如上所述的本发明的虚拟信道(VC)方面被用于在单个物理EGIO链路112中定义单独的逻辑通信接口。在这方面,单独的VC被用于映射流量,所述流量将从不同操作策略和服务优先级中获益。例如,就确保T时间段内所传输的数据量X而言,需要确定性服务质量的流量可以被映射到同步(时间相关)虚拟信道。映射到不同虚拟信道的事务相互之间可以没有任何排序需求。即,虚拟信道作为单独逻辑接口来操作,其具有不同的流控制规则和属性。
对于由主处理器102发起的流量,虚拟信道可以要求基于缺省排序机制规则的排序控制,或者可以完全乱序地操作流量。根据一个示例性实现,VC包含下列两种类型的流量:通用IO流量和同步流量。即,根据该示例性实现,描述了两类虚拟信道:(1)通用IO虚拟信道,和(2)同步虚拟信道。
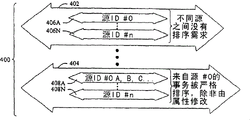
这里所使用的事务层202为组件主动支持的一个或多个虚拟信道中的每个虚拟信道维护独立流控制。这里所使用的所有的EGIO兼容组件一般都会支持缺省通用IO类型虚拟信道,例如虚拟信道0,其中在这一类型的不同虚拟信道之间不需要排序关系。缺省地,VC 0被用于通用IO流量,而VC 1被分配用于操作同步流量。在另一个实现中,任何虚拟信道都可以被分配用于操作任何流量类型。参考图4,示出了包括多条独立管理的虚拟信道的EGIO链路的概念示图。
转到图4,根据本发明的一个方面,示出了包括多条虚拟信道(VC)的示例性EGIO链路112的示图。根据图4所示的示例性实现,所示出的EGIO链路112包括在(多个)EGIO接口106之间创建的多条虚拟信道402、404。根据一个示例性实现,对于虚拟信道402,示出了来自多个源406A...N的流量,这些流量至少由它们的源ID来区分。如图所示,建立了虚拟信道402,并且在来自不同源(例如,代理、接口等)的事务之间没有排序需求。
类似地,所示出的虚拟信道404包括来自多个源多个事务408A...N的流量,其中每个事务由至少一个源ID指示。根据图示的示例,来自源ID 0 406A的事务被严格排序,除非被事务头部的属性字段304所修改,而来自源408N的事务没有这样的排序规则。下文参考图10,提出了一种建立和管理(多条)虚拟信道的示例性方法。
事务排序
尽管使所有响应依次序被处理可能更简单,但是事务层202试图通过准许事务的重新排序来提高性能。为了便于这样的重新排序,事务层202“标记”事务。即根据一个实施例,事务层202添加事务描述符到每个分组,使得它的传输时间可以由EGIO体系结构中的元件来优化(例如,通过重新排序),且不会丢失分组最初被处理的相对顺序。这样的事务描述符被用于辅助请求和完成分组通过EGIO接口层次结构而进行路由。
因而,EGIO互连体系结构和通信协议的创新方面之一是它提供了乱序通信,从而通过减少空闲或等待状态来提高数据吞吐率。在这方面,事务层202使用了一组规则来定义EGIO事务的排序需求。定义了事务排序需求来确保软件的正确操作,所述软件被设计成支持生产者-消费者排序模型,同时允许基于不同排序模型(例如,用于图形附属应用的松散排序)的应用的增加的事务操作灵活性。下文描述了两种不同类型的排序需求:单个排序平面模型和多个排序平面模型。
·基本事务排序-单个“排序平面”模型
假定以下两个组件通过与图1相似的EGIO体系结构连接起来:存储器控制中心,提供到主处理器和存储器子系统的接口;以及IO控制中心,提供到IO子系统的接口。两个中心都含有用于操作输入和输出流量的内部队列,并且在这个简单模型中所有IO流量都被映射到单个“排序平面”。(注意,事务描述符源ID信息为EGIO层次结构中的每个代理都提供了唯一的标识符。还要注意,映射到源ID的IO流量可以携带不同事务排序属性)。在IO发起(IO-initiated)的流量和主机发起(host-initiated)的流量之间规定了本系统配置的排序规则。从这个观点来看,映射到源ID的IO流量和主处理器发起的流量代表在单个“排序平面”中传递的流量。
参考表II,下面提供了该事务排序规则的一个示例。该表中定义的规则普遍适用于包括存储器、IO、配置和消息的EGIO系统中的所有类型的事务。在下面的表II中,列代表两个事务的第一个,而行代表第二个。表条目指明了两个事务之间的排序关系。表条目定义如下:
是-一般会允许第二个事务超过第一个事务以避免死锁。(当发生阻塞时,需要第二个事务超过第一个事务。一般应当考虑公平以防止饥饿(starvation))。
Y/N-没有需求。第一个事务可选地超过第二个事务或者被其阻塞。
否-一般不会允许第二个事务超过第一个事务。这需要保持严格的排序。
| 行超过列? | WR_Req(没有完成请求)(第2列) | RD_Req(第3列) | WR_Req(完成请求)(第4列) | RD_Comp(第5列) | WR_Comp(第6列) |
| WR_Req没有完成请求(第A行) | 否 | 是 | a.否b.是 | Y/N | Y/N |
| RD_Req(第B行) | 否 | a.否b.Y/N | Y/N | Y/N | Y/N |
| WR_Req(完成请求) | 否 | Y/N | a.否b.Y/N | Y/N | Y/N |
| (第C行) | |||||
| RD_Comp(第D行) | 否 | 是 | 是 | a.否b.Y/N | Y/N |
| WR_Comp(第E行) | Y/N | 是 | 是 | Y/N | Y/N |
表II:单个排序平面的事务排序和死锁避免
| 行:列ID | 表II条目的解释 |
| A2 | 公布(post)的存储器写入请求(WR_REQ)一般不应该超过其它任何公布的存储器写入请求 |
| A3 | 一般应该允许公布的存储器写入请求超过读取请求以避免死锁 |
| A4 | a.一般不应该允许公布的存储器WR_REQ超过具有需要完成属性的存储器WR_REQ.b.一般应该允许公布的存储器WR_REQ超过IO和配置请求以避免死锁 |
| A5,A6 | 不需要公布的存储器WR_REQ超过完成。为了允许这一实现的灵活性,同时仍确保无死锁操作,EGIO通信协议规定代理确保完成的接收 |
| B2,C2 | 这些请求不能超过公布的存储器WR_REQ,从而保持支持生产者/消费者用途模型所需的严格写入排序 |
| B3 | a.在基本实现(即,没有乱序处理)中读取请求不准许互相超过。b.在另一个实现中,读取请求准许互相超过。事务标识对于提供这个功能很重要。 |
| B4,C3 | 准许不同类型的请求相互阻塞或超过。 |
| B5,B6,C5,C6 | 准许这些请求被完成阻塞或超过完成。 |
| D2 | 读取完成不能超过公布的存储器WR_Req(以保持严格 |
| 的写入排序) | |
| D3,D4,E3,E4 | 一般应该允许完成超过未公布的请求以避免死锁 |
| D5 | a.在基本实现中,不准许读取完成互相超过;b.在另一个实施例中,准许读取完成互相超过。再者,可能需要严格事务标识。 |
| E6 | 准许这些完成互相超过。对于使用例如事务ID机制来维持事务的轨迹很重要 |
| D6,E5 | 不同类型的完成可以互相超过。 |
| E2 | 准许写入完成被公布的存储器WR_REQ阻塞或超过公布的存储器WR_REQ。该写入事务实际上向相反方向运动,因而没有排序关系 |
表III:事务排序解释
·高级事务排序-“多个平面”事务排序模型
前述部分定义了单个“排序平面”内的排序规则。如上所述,EGIO互连体系结构和通信协议使用唯一的事务描述符机制来将事务和额外的信息相关联,以支持更复杂的排序关系。事务描述符中的字段允许创建多个“排序平面”,从IO流量排序来看这些排序平面是互相独立的。每个“排序平面”都包括对应于具体IO设备(由唯一的源ID指定)的排队/缓冲逻辑,以及传输主处理器发起的流量的排队/缓冲逻辑。“平面”内的排序一般只在这两者之间定义。对独立于其它“排序平面”的每个“排序平面”都实施了在前述部分规定的用来支持生产者/消费者用途模型并且防止死锁的规则。例如,由“平面”N发起的请求的读取完成可以绕过由“平面”M发起的请求的读取完成。然而,平面N的读取完成和平面M的读取完成都不能绕过由主机发起的公布存储器写入。
尽管平面映射机制的使用允许存在多个排序平面,但是排序平面中的一些或全部可以“折叠”到一起以简化实现(即,将多个单独控制的缓冲器/FIFO结合成单个)。当所有平面折叠在一起时,仅使用事务描述符源ID机制来辅助事务的路由,并且它不用于在IO流量的独立流之间松散排序。
除上述内容以外,事务描述符机制还规定了使用排序属性在单个排序平面内修改缺省排序。从而可以以每个事务为基础而控制排序的修改。
事务层协议分组格式
如上所述,创新EGIO体系结构使用基于分组的协议以在相互通信的两个设备的事务层之间交换信息。EGIO体系结构通常支持存储器、IO、配置和消息事务类型。一般使用请求或完成分组传输这些事务,其中只有当需要时,即需要返回数据或请求确认事务的接收时,才使用完成分组。
参考图6,其示出了根据本发明教导的示例性事务层协议的示图。根据图9所示的示例性实现,所示出的TLP头部600包括格式字段、类型字段、扩展类型/扩展长度(ET/EL)字段和长度字段。注意,某些TLP在头部之后包括由头部中规定的格式字段所确定的数据。TLP不应含有多于MAX_PAYLOAD_SIZE设定的极限的数据。根据一个示例性实现,TLP数据是4字节自然对齐的,并且以4字节双字(DW)增加。
如这里所使用的,根据下面的定义,格式(FMT)字段规定了TLP的格式:
·000-2DW头部,无数据
·001-3DW头部,无数据
·010-4DW头部,无数据
·101-3DW头部,有数据
·110-4DW头部,有数据
·预留所有其它的编码
类型字段用于指示TLP中使用的类型编码。根据一个实现,一般应该将格式[2:0]和类型[3:0]解码来确定TLP格式。根据一个实现,类型[3:0]字段中的值用于确定扩展类型/扩展长度字段是否被用于扩展类型字段或长度字段。ET/EL字段一般只用于扩展存储器类型读取请求的长度字段。
长度字段提供了有效载荷长度的指示,还是以DW增加:
00000000=1DW
00000001=2DW
......
11111111=256DW
下面,在表IV中提供了示例性TLP事务类型的至少一个子集、它们对应的头部格式以及描述的总结:
| TLP类型 | 格式[2:0] | 类型[3:0] | Et[1:0] | 描述 |
| 初始FCP | 000 | 0000 | 00 | 初始流控制信息 |
| 更新FCP | 000 | 0001 | 00 | 更新流控制信息 |
| MRd | 001010 | 1001 | E19E18 | 存储器读取请求Et/E1字段用于长度[9:8] |
| MRdLK | 001010 | 1011 | 00 | 存储器读取请求-锁定 |
| MWR | 101110 | 0001 | 00 | 存储器写入请求-公布 |
| IORd | 001 | 1010 | 00 | IO读取请求 |
| IOWr | 101 | 1010 | 00 | IO写入请求 |
| CfgRd0 | 001 | 1010 | 01 | 配置读取类型0 |
| CfgWr0 | 101 | 1010 | 01 | 配置写入类型0 |
| CfgRd1 | 001 | 1010 | 11 | 配置读取类型1 |
| CfgWr1 | 101 | 1010 | 11 | 配置写入类型1 |
| Msg | 010 | 011s2 | s1s0 | 消息请求-子字段s[2:0]规定一组消息。根据一个实现,该消息字段被解码以确定包括是否需要完成在内的专用周期 |
| MsgD | 110 | 001s2 | s1s0 | 带有数据的消息请求-子字段s[2:0]规定一组消息。根据一个实现,该 |
| 消息字段被解码以确定包括是否需要完成在内的专用周期 | ||||
| MsgCR | 010 | 111s2 | s1s0 | 需要完成的消息请求-子字段s[2:0]规定一组消息。根据一个实现,该消息字段被解码以确定专用周期 |
| MsgDCR | 110 | 111s2 | s1s0 | 需要完成且带有数据的消息请求-子字段s[2:0]规定一组消息。根据一个实现,决定专门周期字段以确定专门周期 |
| CPL | 001 | 0100 | 00 | 不带数据的完成-用于具有除成功完成之外的完成状态的IO和配置写入完成、某些消息完成和存储器读取完成 |
| Cp1D | 101 | 0100 | 00 | 带有数据的完成-用于存储器、IO和配置读取完成,以及某些消息完成 |
| Cp1DLk | 101 | 001 | 01 | 锁定存储器读取的完成-否则与Cp1D类似 |
表IV:TLP类型总结
附录A中提供了有关请求和完成的其它细节,其中的说明在这里作为参考而被明确引入。
流控制
与传统流控制方案普遍关联的限制之一是它们对可能发生的问题有反应(reactive),而不是事前预先(proactively)降低发生这些问题发生的机会。例如在传统的PCI系统中,发送者将向接收者发送信息直到它接收到停止/中止发送的消息,其中停止/中止发送直到下一个通知。这些请求之后可能跟随有重新发送起始于发送的给定点处的分组的请求。本领域技术人员将会意识到,这一反应(reactive)方法导致周期浪费,并且在这方面可能效率较低。
为了解决这个限制,EGIO接口106的事务层202包括流控制机制,其预先降低发生溢出情况的机会,同时还规定以发起者和(多个)完成者之间建立的虚拟信道的每个链路为基础来遵守排序规则。根据本发明的一个方面,引入了流控制“信用量”(credit)的概念,其中接收者共享下列信息:(a)缓冲器大小(以信用量为单位),和(b)对于发送者和接收者之间建立的每条虚拟信道(即以每条虚拟信道为基础)的发送者当前可用缓冲器空间。这使得发送者的事务层202能够维护可用缓冲器空间的估值(例如,可用信用量的计数),并且如果确定发送将在接收缓冲器内产生溢出情况则能够预先节流通过任何虚拟信道进行的发送,其中所述可用缓冲器空间分配给通过识别出的虚拟信道进行的发送。
根据本发明的一个方面,如上所述,事务层202引入流控制来防止接收缓冲器的溢出,并使得能够遵循排序规则。根据一个实现,由发送者使用处理层202的流控制机制,以通过EGIO链路112来跟踪代理(接收者)中的可用队列/缓冲器空间。这里所使用的流控制并非暗示请求已经到达它的最终完成器。
根据本发明的教导,流控制与数据完整性机制相互独立,其中所述数据完整性机制用于实现发送者和接收者之间的可靠信息交换。即,流控制能够保证从发送者到接收者的事务层分组(TLP)信息流完好,这是由于数据完整性机制保证通过重新传输来改正出错的和丢失的TLP。这里所使用的流控制机制包括EGIO链路112的虚拟信道。在这方面,将在由接收者通告的流控制信用量(FCC)中反映接收者所支持的每个虚拟信道。
根据本发明的教导,由事务层202和数据链路层204合作来执行流控制。为了方便描述流控制机制,区分出下列分组信息类型:
(a)公布请求头部(PRH)
(b)公布请求数据(PRD)
(c)非公布请求头部(NPRH)
(d)非公布请求数据(NPRD)
(e)读取、写入和消息完成头部(CPLH)
(f)读取和消息完成数据(CPLD)
如上所述,预先流控制的EGIO实现中的测量单位是流控制信用量(FCC)。根据仅仅一个实现,对于数据,流控制信用量是16字节。对于头部,流控制信用量的单位是一个头部。如上所述,每个虚拟信道都具有独立的流控制。对于每个虚拟信道,为上述类型分组信息中的每一类(如上所述的(a)-(f))维护和跟踪单独的信用量指示符。根据所图示的示例性实现,分组的发送根据下述内容来消耗流控制信用量:
-存储器/IO/配置读取请求:1NPH单位
-存储器写入请求:1PH+nPD单位(其中n与数据有效载荷的
大小相关联,例如由流控制单位大小(例如,16字节)划分的数据的长度)
-IO/配置写入请求:1NPH+1NPD
-消息请求:取决于消息,至少1PH和/或1NPH单位
-带有数据的完成:1CPLH+nCPLD单位(其中n与由例如16字节的流控制数据单位大小划分的数据大小有关)
-没有数据的完成:1CPLH
对于所跟踪的每种类型的信息,有三个概念寄存器来监测消耗的信用量(发送者内)、信用量极限(发送者内)和分配的信用量(接收者内),每个概念寄存器有8位宽。信用量消耗寄存器含有自从初始化以来所消耗的流控制单元的模256的总量的计数。在初始化时,信用量消耗寄存器被设定为全零(0),并且当事务层提交(commit)以发送信息到数据链路层时增加该寄存器。增加的大小与提交发送的信息所消耗的信用量数量有关。根据一个实现,当达到或超过最大计数(例如,全1)时,计数器翻转为零。根据一个实现,使用无符号8位模运算来维护计数器。
信用量极限寄存器含有可能消耗的流控制单元的最大数值的极限。在接口初始化时,该寄存器被设定为全零,并且随后在接收消息后被更新并设置为流控制更新消息(上文进行了介绍)中所指示的值。
信用量分配寄存器维护了自从初始化以来授予发送者的信用量总数的计数。根据接收者的缓冲器大小和分配策略来初始设定该计数。该值可以包括在流控制更新消息中。该值随着接收者事务层从它的接收缓冲器移除已处理的信息而增加。增加的大小与所产生的可用空间的大小有关。根据一个实施例,接收者一般应将所分配的信用量最初设定为等于或大于下列值的值:
-PRH:1流控制单位(FCU);
-PRD:FCU等于设备最大有效载荷大小的最大可能设定;
-NPH:1FCU
-NPD:FCU等于设备最大有效载荷大小的最大可能设定;
-交换设备-CPLH:1FCU;
-交换设备-CPLD:FCU等于设备最大有效载荷大小的最大可能设定和设备将会产生的极大读取请求中的较小的一个。
-根和端点设备-CPLH或CPLD:255FCU(全1),发送者认为该值无穷大,因而其从不会阻塞。
根据这样的实现,接收者一般不会为任何消息类型而将信用量分配寄存器值设定为大于127FCU。
根据另一个实现,与上述使用计数器方法维护信用量分配寄存器不同,发送者可以基于下述等式动态计算所分配的信用量:
C_A=(最近接收的发送的信用量单位数)+(可用的接收缓冲器空间)
如上所述,发送者将为发送者将使用的每个虚拟信道实现概念寄存器(消耗的信用量,信用量极限)。类似地,接收者为接收者所支持的每个虚拟信道实现概念寄存器(所分配的信用量)。为了预先制止如果这样做将引起接收缓冲器溢出的信息的发送,如果消耗的信用量的计数加上与将要发送的数据相关的信用量单位数小于或等于信用量极限值,则允许发送者发送一类信息。当发送者接收到指示非无穷信用量(即,<255FCU)的完成的流控制信息(CPL)时,发送者将根据可用信用量来对完成进行节流。当考虑信用量使用及返回时,来自不同事务的信息不混合在一个信用量中。类似地,当考虑信用量使用及返回时,来自一个事务的头部和数据信息也从不混合在一个使用中。因此,当某个分组由于缺乏流控制信用量而被阻塞传输时,发送者在确定应当准许哪个类型的分组绕过“停滞”(stalled)分组时将遵循排序规则(上文)。事务的流控制信用量的返回不被解释为意味着事务已经完成或事务已经实现系统可见性(visibility)。使用存储器写入请求语义的消息信号中断(MSI)象其它任何存储器写入一样被处理。如果随后的FC更新消息(来自接收者)指示了比最初指示的值更低的信用量极限值,则发送者应当承认新的较低极限,并且提供一个消息差错。
根据这里所描述的流控制机制,如果接收者接收到比分配的信用量更多的信息(超过分配的信用量),则接收者将向违规的发送者指示接收者溢出差错,并且对引起溢出的分组发起数据链路级别的重试请求。
·流控制分组(FCP)
根据一个实现,使用流控制分组(FCP)在设备之间传输维护上述寄存器所需的流控制信息。根据一个实施例,流控制分组900包括2-DW头部格式和用于具体虚拟信道的关于六个信用量寄存器的状态的输送信息,其中所述的六个信用量寄存器由接收事务层的流控制逻辑为每个VC维护。根据本发明的教导的一个实施例,如图6所示,有两种类型的FCP:初始FCP和更新FCP。
如上所述,在初始化事务层时,发布初始FCP 602。在初始化事务层之后,更新FCP 604被用于更新寄存器中的信息。在常规操作期间接收到初始FCP引起本地流控制机制的复位以及初始FCP的发送。初始FCP的内容包括为PRH、PRD、NPRH、NPRD、CPH、CPD和信道ID(例如,与应用FC信息相关联的虚拟信道)中的每个所通告的信用量的至少一个子集。更新FCP的格式与初始FCP的格式类似。注意,尽管FC头部不包括其它事务层分组头部格式普遍具有的长度字段,但是分组的大小是明确的,因为没有与该分组相关的额外DW数据。
差错转发
与传统的差错转发机制不同,EGIO体系结构依靠尾部信息,所述尾部信息被附加到由于如下描述的多个原因中的任何原因而被识别为有缺陷的(多个)数据报上。根据一个示例性实现,事务层202使用了多种公知差错检测技术中的任何一种,例如循环冗余校验(CRC)差错控制等等。
根据一个实现,为了有助于差错转发特征,EGIO体系结构使用了“尾部”,其附加到携带已知坏数据的TLP上。可能使用尾部差错转发的情况示例包括:
示例#1:来自主存储器的读取遇到无法纠正的ECC差错
示例#2:向主存储器的PCI写入的奇偶差错
示例#3:内部数据缓冲器或缓存中的数据完整性差错
根据一个示例性实现,差错转发仅用于读取完成数据或写入数据。即,对于与数据报相关的管理开销中发生差错的情形,例如头部中的差错(例如请求阶段、地址/命令等等),一般不使用差错转发。这里所使用的具有头部差错的请求/完成通常不能被转发,这是由于不能确定地识别真正目的地,并且因此该差错转发可能引起直接或间接影响,例如数据损坏、系统故障等等。根据一个实施例,差错转发用于通过系统传播差错,系统诊断。差错转发不使用数据链路层重试,因此只有在EGIO链路112上出现如TLP差错检测机制(例如,循环冗余校验(CRC)等等)所确定的发送差错时,才重试以尾部结束的TLP。因此尾部可能最终引起请求的发起者重新发布它(在上述的事务层)或者采取某个其它的动作。
这里所使用的所有EGIO接收者(例如,位于EGIO接口106中)都能够处理以尾部结束的TLP。在发送者中对加入尾部的支持是可选的(因而与老式设备兼容)。交换器108将尾部和TLP的其余部分一起进行路由。具有对等(peer)路由支持的主桥104一般会一起路由尾部和TLP的其余部分,但不是必须如此。差错转发一般适用于写入请求(公布的或非公布的)或读取完成中的数据。发送者知道的含有坏数据的TLP应当以尾部结束。
根据一个示例性实现,尾部由2DW组成,其中字节[7:5]是全零(例如,000),并且位[4:1]是全一(例如,1111),而预留所有其它位。EGIO接收者会认为以尾部结束的TLP中的所有数据都是损坏的。
如果应用差错转发,则接收者将指定TLP的所有数据标记为坏(“中毒”)。在事务层中,分析器(parser)一般会对整个TLP的末端进行分析并马上校验随后的数据,以了解数据是否结束。
数据链路层204
如上所述,图2的数据链路层204充当事务层202和物理层206之间的中间级(intermediate stage)。数据链路层204的主要责任是提供用于通过EGIO链路112在两个组件之间交换事务层分组(TLP)的可靠机制。数据链路层204的发送方接受由事务层202装配的TLP、应用分组序列标识符(例如,标识号码)、计算并应用差错检测代码(例如,CRC代码)并且向物理层206递交修改的TLP,用于通过挑选的一条或多条在EGIO链路112的带宽中建立的虚拟信道而进行传输。
接收数据链路层204负责校验所接收TLP的完整性(例如,使用CRC机制等等),并且负责向事务层204递交完整性校验是肯定的那些TLP,以用于在转发到设备核心之前进行分解。
由数据链路层204提供的服务通常包括数据交换、差错检测与重试、初始化与电源管理服务,以及数据链路层内部通信服务。基于前述分类提供的每种服务列举如下。
数据交换服务
-从发送事务层接受用于发送的TLP
-接受通过链路从物理层接收的TLP,并将它们传输到接收事务层差错检测和重试
-TLP序列号码与CRC生成
-存储所发送的TLP,用于数据链路层重试
-数据完整性校验
-确认以及重试DLLP
-用于差错报告和记录机制的差错指示
-链路Ack超时定时器
初始化与电源管理服务
-跟踪链路状态并传输有效/复位/断开连接状态到事务层数据链路层内部通信服务
-用于包括差错检测和重试在内的链路管理功能
-在两个直接相连的组件的数据链路层之间进行传输
-没有暴露给事务层
在EGIO接口106中所使用的数据链路层204对于事务层202表现为具有不同延迟的信息导管(conduit)。馈送到发送数据链路层中的所有信息在晚些时候将出现在接收数据链路层的输出端。延迟将取决于许多因素,包括流水线延迟、链路112的宽度和操作频率、通过介质的通信信号的发送、以及由数据链路层重试引起的延时。由于这些延时,发送数据链路层可以向发送事务层202施加反压力(backpressure),并且接收数据链路层将有效信息的存在和缺失传输到接收事务层202。
根据一个实现,数据链路层204跟踪EGIO链路112的状态。在这方面,DLL 204与事务层202和物理层206传输链路状态,并且通过物理层206执行链路管理。根据一个实现,数据链路层含有链路控制与管理状态机来执行这样的管理任务。此状态机的状态描述如下:
示例性DLL链路状态:
·LinkDown(链路停用)(LD)-物理层报告链路是不可操作的,或者没有连接端口
·LinkInit(链路初始化)(LI)-物理层报告链路是可操作的并且正在初始化
·LinkActive(链路有效)(LA)-常规操作模式
·LinkActDefer(链路动作延期)(LAD)-常规操作中断,物理层试图恢复
每个状态的对应管理规则:(例如,见图8)
·LinkDown(LD)
跟随在组件复位之后的初始状态
在进入LD时:
-将所有数据链路层状态信息复位成缺省值
在LD中时:
-不和事务层或物理层交换TLP信息
-不和物理层交换DLLP信息
-不产生也不接受DLLP
退出到LI,如果:
-来自事务层的指示是链路没有被SW禁用
·LinkInit(LI)
在LI中时:
-不和事务层或物理层交换TLP信息
-不和物理层交换DLLP信息
-不产生也不接受DLLP
退出到LA,如果:
-来自物理层的指示是链路训练(training)成功
退出到LD,如果:
-来自物理层的指示是链路训练(training)失败
·LinkActive(LA)
在LinkActive中时:
-和事务层与物理层交换TLP信息
-和物理层交换DLLP信息
-产生并接受DLLP。
退出到LinkActDefer,如果:
-来自数据链路层重试管理机制的指示是需要链路的重新训练,或者物理层是否报告重新训练正在进行中。
·LinkActDefer(LAD)
在LinkActDefer中时:
-不和事务层或物理层交换TLP信息
-不和物理层交换DLLP信息
-不产生也不接受DLLP
退出到LinkActive,如果:
-来自物理层的指示是重新训练成功
退出到LinkDown,如果:
-来自物理层的指示是重新训练失败
数据完整性管理
这里所使用的数据链路层分组(DLLP)被用于支持EGIO链路数据完整性机制。在这方面,根据一个实现,EGIO体系结构规定了下列DLLP来支持链路完整性管理:
·Ack DLLP:TLP序列号码确认-用于指示成功接收了某个数量的TLP
·Nak DLLP:TLP序列号码否定确认-用于指示数据链路层重试
·Ack超时DLLP:指示最近发送的序列号码-用于检测某些形式的TLP丢失
如上所述,事务层202向数据链路层204提供TLP边界信息,使得DLL 204能够将序列号码和循环冗余校验(CRC)差错检测应用于TLP。根据一个示例性实现,接收数据链路层通过校验序列号码、CRC代码和来自接收物理层的任何差错指示来验证接收的TLP。如果TLP中有差错,则使用数据链路层重试来恢复。
·CRC、序列号码以及重试管理(发送者)
在概念“计数器”和“标志”方面,以下描述了用于确定TLP、CRC和序列号码以支持数据链路层重试的机制:
CRC与序列号码规则(发送者)
·使用下列8位计数器:
o TRANS_SEQ-存储应用于正在准备发送的TLP的序列号码
.在LinkDown状态下设定为全‘0’
.在每个TLP发送后,增加1
.当全‘1’时,增加引起翻转使得全‘0’
.Nak DLLP的接收引起值被重新设定为Nak DLLP中指示的序列号码
o ACKD_SEQ-存储在最近接收的链路到链路确认DLLP中确认的序列号码。
.在LinkDown状态下设定为全‘1’
·每个TLP被分配8位序列号码
o计数器TRANS_SEQ存储这个号码
o如果TRANS_SEQ等于(ACKD_SEQ-1)模256,则发送者一般不会发送另一TLP,直到Ack DLLP更新ACKD_SEQ,使得条件(TRANS_SEQ==ACKD_SEQ-1)模256不再为真。
·TRANS_SEQ被应用于TLP,通过:
o为TLP预先准备(prepend)单个字节值
o为TLP预先准备单个预留字节
·使用下述算法为TLP计算32b CRC,并将其附加在TLP末端
o使用的多项式是0×04C11DB7
-与以太网使用的相同的CRC-32
o计算过程是:
1)CRC-32计算的初始值是通过为序列号码预先准备24个‘0’而形成的DW
2)以从包括头部的字节0的DW到TLP的最后DW的顺序,使用来自事务层的TLP的每个DW而继续CRC计算
3)取来自计算的位序列的补码,结果是TLP CRC
4)将CRC DW附加到TLP的末端
·已发送TLP的拷贝一般会存储在数据链路层重试缓冲器中
·当从其它设备接收到Ack DLLP时:
o ACKD_SEQ装入在DLLP中指定的值
o重试缓冲器清除序列号码在下述范围内的TLP:
.从ACKD_SEQ的先前值+1
.到ACKD_SEQ的新值
·当从链路上的其它组件接收到Nak DLLP时:
o如果正在向物理层传输TLP,则继续该传输直到该TLP的传输完成
o不从事务层获得另外的TLP,直到完成了下述步骤
o重试缓冲器清除序列号码在下述范围内的TLP:
.从ACKD_SEQ的先前值+1
.到在Nak DLLP的Nak序列号码字段中指定的值
o重试缓冲器中所有剩余的TLP都重新提交到物理层,用于以原始顺序重新发送
.注意:这将包括序列号码在下述范围内的所有TLP:
o在Nak DLLP的Nak序列号码字段中指定的值+1
o TRANS_SEQ的值-1
.如果在重试缓冲器中没有剩余的TLP,则Nak DLLP出错
o根据差错跟踪和记录部分,一般会报告差错的Nak DLLP
o发送者不需要其它的动作
·CRC与序列号码(接收者)
类似地,在概念“计数器”和“标志”方面,以下描述了用于确定TLP、CRC和序列号码以支持数据链路层重试的机制:
·使用下列8位计数器:
o NEXT_RCV_SEQ-为下一个TLP存储期望的序列号码
.在LinkDown状态下设定为全‘0’
.对于接受的每个TLP,增加1,或者当通过接受TLP而清除DLLR_IN_PROGRESS标志(下文描述)时
.每次接收到链路层DLLP并且DLLR_IN_PROGRESS标志被清除时,装入值(Trans.Seq.Num+1)
o如果NEXT_RCV_SEQ的值与已接收的TLP或Ack超时DLLP指定的值不同,则指示在发送者和接收者之间的序列号码同步丢失;在这种情况下:
.如果设定了DLLR_IN_PROGRESS标志,则
o复位DLLR_IN_PROGRESS标志
o发送“发送坏DLLR DLLP”差错到差错记录/跟踪
o注意:这指示错误地发送了DLLR DLLP(Nak)
.如果没有设定DLLR_IN_PROGRESS标志,则
o设定DLLR_IN_PROGRESS标志并且发起Nak DLLP
o注意:这指示TLP丢失
·使用下述3位计数器:
o DLLRR_COUNT-对在特定时间段内发出的DLLR DLLP的次数进行计数
.在LinkDown状态下设定为b’100
.对于发布的每个Nak DLLP,增加1
.当计数达到b’100时:
o链路控制状态机从LinkActive移动到LinkActDefer
o DLLRR_COUNT随后被复位为b’000
.如果DLLRR_COUNT不等于b’000,每256个符号时间减1
o即,在b’000饱和
·使用下述标志:
o DLLR_IN_PROGESS
.下面描述设定/清除条件
.当设定了DLLR_IN_PROGESS时,丢弃所有已接收的TLP(直到接收到由DLLR_DLLP指示的TLP)
.当DLLR_IN_PROGESS是清空的时,如下所述校验已接收的TLP
·对于将要接受的TLP,下述条件一般应当为真:
o已接收的TLP序列号码等于NEXT_RCV_SEQ
o物理层没有指示在TLP接收过程中的任何差错
o TLP CRC校验不指示差错
·当接受了TLP时:
o TLP的事务层部分被转发到接收事务层
o如果设定,则清空DLLR_IN_PROGESS标志
o增加NEXT_RCV_SEQ
·当没有接受TLP时:
o设定DLLR_IN_PROGESS标志
o发送Nak DLLP
.Ack/Nak序列号码字段一般应包含值(NEXT_RCV_SEQ-1)
.Nak类型(NT)字段一般会指示Nak的原因
o b’00-由物理层识别的接收差错
o b’01-TLP CRC校验失败
o b’10-序列号码不正确
o b’11-由物理层识别的成帧差错
·接收者一般不会允许从接收TLP的CRC到发送Nak的时间超过1023个符号时间,如从组件的端口所测量的那样。
o注意:没有增加NEXT_RCV_SEQ
·如果接收数据链路层没有接收到在其后的512个符号时间内跟随着Nak DLLP的期望TLP,则重复Nak DLLP。
o如果经过四次尝试后仍然没有接收到期望的TLP,则接收者将:
.进入LinkActDefer状态,并启动由物理层进行的链路重新训练
.将主要差错的发生指示给差错跟踪与记录
·当下列条件为真时,一般会发送数据链路层确认DLLP:
o数据链路控制与管理状态机处于LinkActive状态
o已经接受了TLP,但还没有通过发送确认DLLP进行确认
o从最后的确认DLLP起已经经过了超过512个符号时间
·可以比所需要的更频繁地发送数据链路层确认DLLP
·数据链路层确认DLLP在Ack序列Num字段内规定值(NEXT_RCV_SEQ-1)
·Ack超时机制
考虑TLP在链路112上被损坏使得接收者未检测到TLP的存在的情况。当发送随后的TLP时将检测到丢失的TLP,因为TLP序列号码与接收者处的期望序列号码不匹配。然而,发送数据链路层204通常不能限定下一TLP从发送传输层到在发送数据链路层204上面出现的时间。Ack超时机制允许发送者限定接收者所需的检测丢失TLP的时间。
Ack超时机制规则
·如果发送重试缓冲器含有没有接收到Ack DLLP的TLP,并且如果在超过1024个符号时间的时间段内没有发送TLP或链路DLLP,则一般会发送Ack超时DLLP。
·在发送Ack超时DLLP之后,数据链路层一般不会传送任何TLP到物理层用于发送,直到从链路的另一方的组件接收到确认DLLP。
o如果在超过1023个符号时间的时间段内没有接收到确认DLLP,则再次发送Ack超时DLLP
-在第四次连续发送Ack超时DLLP之后的1024个符号时间内仍没有接收到确认DLLP,
.进入LinkActDefer状态并且启动由物理层进行的链路保持
.将主要差错的发生指示给差错跟踪与记录。
物理层206
继续参考图2,示出了物理层206。这里所使用的物理层206使事务层202和数据链路层204与用于链路数据相互交换的信令技术相隔离。根据图2所示的示例性实现,物理层划分为逻辑208和物理210功能子块。
这里所使用的逻辑子块208负责物理层206的“数字”功能。在这方面,逻辑子块204具有两个主要部分:发送部分,准备输出信息用于由物理子块210进行发送;以及接收者部分,用于在将所接收信息传送到链路层204之前识别并准备该信息。逻辑子块208和物理子块210通过状态与控制寄存器接口协调端口状态。由逻辑子块208指导物理层206的控制与管理功能。
根据一个示例性实现,EGIO体系结构使用8b/10b发送代码。使用该方案,8位字符被视为3位和5位,所述3位和5位各自映射到4位代码组和6位代码组。这些代码组被链接以形成10位符号。EGIO体系结构使用的8b/10b编码方案提供了专用符号,其与用来表示字符的数据符号完全不同。这些专用符号用于下面的多种链路管理机制。专用符号还用于将DLLP和TLP成帧,使用完全不同的专用符号来允许快速便捷地区分这两类分组。
物理子块210包括发送者和接收者。逻辑子块208向发送者供应符号,发送者串行化这些符号并将其发送到链路112。从链路112向接收者供应串行化符号。接收者将所接收信号转换为位流,位流被解串行化,并且连同从输入串行流中恢复的符号时钟一起被供应到逻辑子块208。应当理解,这里所使用的EGIO链路112可以代表多种通信介质中的任何一种,所述多种通信介质包括电通信链路、光通信链路、RF(射频)通信链路、红外线通信链路、无线通信链路等等。在这方面,包括物理层206的物理子块210的(多个)发送者和/或(多个)接收者中的每一个都适合于一种或多种上述通信链路。
示例性通信代理
图5示出了根据本发明的一个示例性实现,含有与本发明相关联的特征的至少一个子集的示例性通信代理的方框图。根据图5所示的示例性实现,所示出的通信代理500包括控制逻辑502、EGIO通信引擎504、用于数据结构506的存储器空间,以及可选的一个或多个应用508。这里所使用的控制逻辑502向EGIO通信引擎504的一个或多个元件中的每个提供处理资源,以选择性地实现本发明的一个或多个方面。在这个方面,控制逻辑502意在代表微处理器、微控制器、有限状态机、可编程逻辑组件、现场可编程门阵列,或当执行时使控制逻辑实现上述之一功能的内容中的一个或多个。
所示出的EGIO通信引擎504包括事务层接口202、数据链路层接口204和物理层接口206中的一个或多个,所述物理层接口206包括逻辑子块208和物理子块210,以将通信代理500和EGIO链路112相接口。这里所使用的EGIO通信引擎504的元件执行与上述的功能相同或类似的功能。
根据图5所示的示例性实现,所示出的通信代理500包括数据结构506。如下文参考图7将要详细介绍的,数据结构506可以包括存储器空间、IO空间、配置空间和消息空间,所述空间由通信引擎504使用以便于EGIO体系结构的元件之间进行通信。
这里所使用的应用508意在代表由通信引擎500选择性调用的多种应用的任何一种,以实现EGIO通信协议和相关的管理功能。
示例性(多种)数据结构
转到图7,示出了根据本发明的一个实现,(多个)EGIO接口106所使用的一种或多种数据结构。更具体地说,参考图7所示的示例性实现,定义了四(4)个地址空间以在EGIO体系结构中使用:配置空间710、IO空间720、存储器空间730以及消息空间740。如图所示,配置空间710包括头部字段712,其定义了主设备所属的EGIO类别(例如端点等等)。这些地址空间的每个都执行他们如上所述的各自功能。
以上已经参考图1-8,介绍了与本发明相关联的体系结构和协议的要素,现在将注意力转向图10,其中提出了一种管理增强型通用输入/输出体系结构的物理通信资源的示例性方法。
转到图10,根据本发明的一个示例性实施例,提出了在增强型通用输入/输出链路的物理资源中建立和管理一条或多条虚拟信道的示例性方法的流程图。根据图10所示的示例性实现,该方法开始于方框1002,其中EGIO接口106接收到用于发送给另一组件的信息。根据一个示例性实现,EGIO接口106的事务层202从主组件中的处理代理接收到所述信息。
在方框1004中,EGIO接口106确定所接收的信息是与已建立的虚拟信道相关联,还是需要新的虚拟信道。根据一个实现,事务层202通过识别所述信息的源和目的地来进行该确定。如果在方框1004中,事务层202将所述信息识别为与现有虚拟信道相关联,则事务层202产生与合适的虚拟信道相关联的事务层分组(TLP),以通过物理链路层206将所接收的信息传送到合适的虚拟信道,用于通过物理通用输入/输出资源来传输,方框1006。
如果在方框1004中,所述信息需要创建新的虚拟信道,则事务层202还对所需虚拟信道的类型进行进一步确定,方框1008。根据一个示例性实现,事务层202至少部分地基于所接收的信息内容来进行此确定。根据上述一个示例性实现,EGIO体系结构提供对多种类型虚拟信道的支持,基于与要传送的信息相关联的服务质量需求来选择这些类型。在这方面,事务层202确定所接收的信息是不是时间相关(等时)的,如果是,则建立一条或多条等时虚拟信道,以支持对这种信息的传输。根据一个实施例,内容的类型是通过对该内容自身的分析而确定的,或者是从将所述内容传递到事务层的代理类型(例如,应用的类型)来推断的。
在方框1012中,EGIO接口106建立具有单独的流控制和排序规则的虚拟信道,用该虚拟信道来通过EGIO链路112的物理资源将信息发送给另一组件。更具体地说,如上所述,事务层202产生指示虚拟信道类型的事务层分组,用于通过数据链路层204传递到物理层206,以便路由到EGIO链路112的物理介质上。根据本发明的教导,如上所述,事务层202为由事务层202建立的每条虚拟信道保持单独的流控制和排序规则。在这方面,已经描述了体系结构、协议及有关方法,用于在EGIO链路112的物理资源中建立和管理多条虚拟信道。
其它实施例
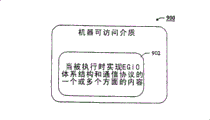
图9是根据本发明另一个实施例的其上存有多个指令的存储器介质的方框图,其中所述指令包括实现EGIO互连体系结构和通信协议的一个或多个方面的指令。大体而言,图12示出了其上(中)存储有内容的机器可访问介质/设备900,所述内容包括以下内容的至少一个子集,即当访问机器执行所述内容时,所述内容实现了本发明的创新EGIO接口106。
这里所使用的机器可访问介质900意在代表本领域技术人员公知的多种介质中的任何一种,例如易失性存储器设备、非易失性存储器设备、磁存储介质、光存储介质、传播信号等等。类似地,可执行指令意在反映本领域公知的多种软件语言中的任何一种,例如C++、Visual Basic、超文本标记语言(HTML)、Java、可扩充标记语言(XML)等等。此外,应当认识到介质900不需要与任何主系统共处在一起。即,介质900可以位于远程服务器中,所述服务器可通信地耦合到执行系统并可由执行系统访问。因此,图9的软件实现应当认为是示例性的,因为代替性的存储介质与软件实施例被认为位于本发明的精神和范围之内。
尽管以详细的描述以及对结构特征和/或方法步骤的专用语言的抽象描述了本发明,但是应当理解,在所附权利要求中定义的本发明不必限制为所描述的具体特征或步骤。相反,所述具体特征和步骤只是作为实现所主张的发明的示例性形式而被公开。然而很明显,可以对其进行各种修改和变化而不会背离本发明较宽的精神和范围。因此本说明书和附图被认为是示例性的而不是限制性的。说明书和摘要没有被规定为是穷尽性的或是要将本发明限制为所公开的确定形式。
所附权利要求中使用的术语不应被解释成将本发明限制为说明书中公开的具体实施例。相反,所附权利要求完全确定了本发明的范围,其中根据已有权利要求解释原则来解释所述权利要求。
Claims (32)
1. 一种用于在增强型通用输入/输出体系结构中建立虚拟信道的方法,包括:
接收用于通过通用输入/输出总线而传输到外部代理的信息;
将所述通用输入/输出总线上总的可用带宽的一个子集动态分配为虚拟信道,以允许将所述信息传输到可通信地耦合的所述外部代理;以及
至少部分地基于所接收的信息的内容,识别虚拟信道的类型,所述信息是通过所述虚拟信道而被允许传输的。
2. 如权利要求1所述的方法,识别虚拟信道的类型包括:
确定所接收的信息是否包括等时内容;以及
如果有等时内容,则建立等时虚拟信道以便于传输等时内容。
3. 如权利要求2所述的方法,还包括:
建立通用输入/输出虚拟信道,以便于传输非等时内容。
4. 如权利要求2所述的方法,其中,不探听等时虚拟信道,以允许确定性的服务定时。
5. 如权利要求2所述的方法,其中,根据在所述信息的发送者和接收者之间建立的期望服务质量,建立等时虚拟信道。
6. 如权利要求5所述的方法,其中,根据一段时间内的信息传输来量化所述期望服务质量。
7. 如权利要求2所述的方法,其中,等时内容是时间相关的。
8. 如权利要求1所述的方法,还包括:
在所述通用输入/输出总线的总带宽中建立另外的虚拟信道,以允许传送信息。
9. 一种用于在增强型通用输入/输出体系结构中建立虚拟信道的方法,包括:
接收用于通过通用输入/输出总线而传输到外部代理的信息;
将所述通用输入/输出总线上总的可用带宽的一个子集动态分配为虚拟信道,以允许将所述信息传输到可通信地耦合的组件,其中所述虚拟信道是在所述通用输入/输出总线上建立的多达多条虚拟信道中的一条,其中独立地管理所述虚拟信道中每条信道的状态。
10. 如权利要求9所述的方法,其中,对虚拟信道状态的独立管理包括:
独立地管理一条或多条已建立的虚拟信道中每条信道的流控制。
11. 如权利要求10所述的方法,其中,对虚拟信道状态的独立管理包括:
独立地管理一条或多条己建立的虚拟信道中每条信道的排序规则。
12. 如权利要求10所述的方法,其中,对一条或多条虚拟信道中每条信道的独立管理是在耦合到所述通用输入/输出总线的设备的事务层中执行的。
13. 如权利要求11所述的方法,其中,一条或多条虚拟信道中的每条信道共享所述通用输入/输出总线的物理通信资源。
14. 如权利要求13所述的方法,还包括:
向多条虚拟信道中的任意信道动态分配允许通过所述虚拟信道进行通信所需的物理带宽。
15. 如权利要求14所述的方法,其中,向一条或多条虚拟信道中的每条信道动态分配物理带宽是由耦合到所述通用输入/输出总线的设备的物理层来执行的。
16. 如权利要求9所述的方法,还包括:
建立通用输入/输出虚拟信道,以便于传输非等时内容。
17. 如权利要求9所述的方法,其中,不探听等时虚拟信道,以允许确定性的服务定时。
18. 如权利要求9所述的方法,其中,根据在所述信息的发送者和接收者之间建立的期望服务质量,建立等时虚拟信道。
19. 如权利要求9所述的方法,其中,等时内容是时间相关的。
20. 一种计算设备,包括:
通用输入/输出总线;和
两个或多个组件,其中每个组件都与所述通用输入/输出总线可通信地耦合,其中所述组件中的一个或多个包括增强型通用输入/输出接口,用于建立虚拟信道,所述虚拟信道动态地共享所述通用输入/输出总线的物理资源,以允许在所述两个或多个组件之间传送信息,所述增强型通用输入/输出接口包括:事务层,用于从组件中的一个或多个处理代理接收信息,并建立一条或多条虚拟信道,用所述虚拟信道来将信息从所述一个或多个处理代理传送给一个或多个外部代理。
21. 如权利要求20所述的计算设备,其中,所述事务层对己建立的虚拟信道中的每条信道的状态进行相对于彼此的独立管理。
22. 如权利要求20所述的计算设备,其中,所述事务层至少部分地基于从所述处理代理接收到的信息的内容,从多个虚拟信道类型中选择一类虚拟信道。
23. 如权利要求20所述的计算设备,其中,所述虚拟信道类型包括通用输入/输出虚拟信道类型和等时虚拟信道类型。
24. 如权利要求23所述的计算设备,其中,所述通用输入/输出虚拟信道类型是缺省虚拟信道类型。
25. 如权利要求23所述的计算设备,其中,预留所述等时虚拟信道类型,以便于通过所述通用输入/输出总线在所述处理代理和所述外部代理之间传送等时信息。
26. 如权利要求25所述的计算设备,其中,等时信息包括时间相关的内容。
27. 如权利要求26所述的计算设备,所述增强型通用输入/输出接口包括:
物理链路层,响应于所述事务层,至少部分地基于何时接收到用于通过所述虚拟信道而传输的信息,来管理对分配给一条或多条已建立的虚拟信道中每条信道的物理通用输入/输出总线资源的访问。
28. 如权利要求27所述的计算设备,其中,所述物理链路层优先将物理通用输入/输出总线资源分配给与等时虚拟信道相关联的信息,而非与通用输入/输出虚拟信道相关联的信息。
29. 如权利要求20所述的计算设备,所述增强型通用输入/输出接口包括:
物理链路层,响应于所述事务层,至少部分地基于何时接收到用于通过所述虚拟信道而传输的信息,来管理对分配给一条或多条已建立的虚拟信道中每条信道的物理通用输入/输出总线资源的访问。
30. 如权利要求29所述的计算设备,其中,所述物理链路层至少部分地基于虚拟信道类型,向已建立的虚拟信道中的每条信道动态分配物理通用输入/输出总线资源。
31. 如权利要求30所述的计算设备,其中,物理链路层优先将物理通用输入/输出总线资源分配给与等时虚拟信道相关联的信息,而非与通用输入/输出虚拟信道相关联的信息。
32. 如权利要求31所述的计算设备,其中,物理链路层通过下述事务层分组中的信息来识别虚拟信道类型,所述事务层分组与所接收的用于通过所述虚拟信道而传输的信息相关联。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US09/968,620 | 2001-09-30 | ||
| US09/968,620 US6691192B2 (en) | 2001-08-24 | 2001-09-30 | Enhanced general input/output architecture and related methods for establishing virtual channels therein |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN1561490A CN1561490A (zh) | 2005-01-05 |
| CN100416528C true CN100416528C (zh) | 2008-09-03 |
Family
ID=25514509
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CNB028193067A Expired - Lifetime CN100416528C (zh) | 2001-09-30 | 2002-09-27 | 增强型通用输入/输出体系结构及在其中建立虚拟信道的有关方法 |
Country Status (8)
| Country | Link |
|---|---|
| US (2) | US6691192B2 (zh) |
| EP (1) | EP1433067B1 (zh) |
| KR (1) | KR100611268B1 (zh) |
| CN (1) | CN100416528C (zh) |
| AT (1) | ATE357696T1 (zh) |
| DE (1) | DE60219047T2 (zh) |
| HK (1) | HK1063091A1 (zh) |
| WO (1) | WO2003029995A1 (zh) |
Families Citing this family (56)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| DE69930014T2 (de) * | 1999-12-30 | 2006-09-21 | Nokia Corp. | Wirksame verarbeitung von mehrfachverbindungsverkehr |
| US9836424B2 (en) * | 2001-08-24 | 2017-12-05 | Intel Corporation | General input/output architecture, protocol and related methods to implement flow control |
| EP1421501B1 (en) | 2001-08-24 | 2006-08-02 | Intel Corporation | A general intput/output architecture, protocol and related methods to implement flow control |
| US20030056003A1 (en) * | 2001-09-18 | 2003-03-20 | Bryce Nakatani | Internet broadcast and location tracking method and apparatus |
| US7028132B2 (en) * | 2001-09-29 | 2006-04-11 | Hewlett-Packard Development Company, L.P. | Distributed peer-to-peer communication for interconnect busses of a computer system |
| US6944617B2 (en) * | 2001-12-28 | 2005-09-13 | Intel Corporation | Communicating transaction types between agents in a computer system using packet headers including an extended type/extended length field |
| US7184399B2 (en) * | 2001-12-28 | 2007-02-27 | Intel Corporation | Method for handling completion packets with a non-successful completion status |
| US7191375B2 (en) * | 2001-12-28 | 2007-03-13 | Intel Corporation | Method and apparatus for signaling an error condition to an agent not expecting a completion |
| US7581026B2 (en) * | 2001-12-28 | 2009-08-25 | Intel Corporation | Communicating transaction types between agents in a computer system using packet headers including format and type fields |
| US7099318B2 (en) | 2001-12-28 | 2006-08-29 | Intel Corporation | Communicating message request transaction types between agents in a computer system using multiple message groups |
| US7110413B2 (en) * | 2001-12-31 | 2006-09-19 | Hewlett-Packard Development Company | Downstream broadcast PCI switch |
| US7099814B2 (en) * | 2002-03-29 | 2006-08-29 | International Business Machines Corportion | I/O velocity projection for bridge attached channel |
| US8045548B1 (en) * | 2002-03-29 | 2011-10-25 | Advanced Micro Devices, Inc. | Data stream labeling and processing |
| US7243154B2 (en) * | 2002-06-27 | 2007-07-10 | Intel Corporation | Dynamically adaptable communications processor architecture and associated methods |
| US7065597B2 (en) * | 2002-06-28 | 2006-06-20 | Intel Corporation | Method and apparatus for in-band signaling of runtime general purpose events |
| US20040131072A1 (en) * | 2002-08-13 | 2004-07-08 | Starent Networks Corporation | Communicating in voice and data communications systems |
| US7219176B2 (en) * | 2002-09-30 | 2007-05-15 | Marvell International Ltd. | System and apparatus for early fixed latency subtractive decoding |
| US7917646B2 (en) * | 2002-12-19 | 2011-03-29 | Intel Corporation | Speculative distributed conflict resolution for a cache coherency protocol |
| KR101042080B1 (ko) * | 2003-06-30 | 2011-06-16 | 톰슨 라이센싱 | 파라미터화된 qos 채널로, 및 파라미터화된 qos채널로부터 우선순위화된 qos 패킷을 매핑하기 위한방법 및 장치 |
| US8098669B2 (en) | 2003-08-04 | 2012-01-17 | Intel Corporation | Method and apparatus for signaling virtual channel support in communication networks |
| US20050058130A1 (en) * | 2003-08-04 | 2005-03-17 | Christ Chris B. | Method and apparatus for assigning data traffic classes to virtual channels in communications networks |
| US7101742B2 (en) | 2003-08-12 | 2006-09-05 | Taiwan Semiconductor Manufacturing Company, Ltd. | Strained channel complementary field-effect transistors and methods of manufacture |
| US7609636B1 (en) * | 2004-03-29 | 2009-10-27 | Sun Microsystems, Inc. | System and method for infiniband receive flow control with combined buffering of virtual lanes and queue pairs |
| US7822929B2 (en) * | 2004-04-27 | 2010-10-26 | Intel Corporation | Two-hop cache coherency protocol |
| US20050240734A1 (en) * | 2004-04-27 | 2005-10-27 | Batson Brannon J | Cache coherence protocol |
| US20050262250A1 (en) * | 2004-04-27 | 2005-11-24 | Batson Brannon J | Messaging protocol |
| US20060010276A1 (en) * | 2004-07-08 | 2006-01-12 | International Business Machines Corporation | Isolation of input/output adapter direct memory access addressing domains |
| US7398427B2 (en) * | 2004-07-08 | 2008-07-08 | International Business Machines Corporation | Isolation of input/output adapter error domains |
| US20060010277A1 (en) * | 2004-07-08 | 2006-01-12 | International Business Machines Corporation | Isolation of input/output adapter interrupt domains |
| US7573879B2 (en) * | 2004-09-03 | 2009-08-11 | Intel Corporation | Method and apparatus for generating a header in a communication network |
| US7522520B2 (en) * | 2004-09-03 | 2009-04-21 | Intel Corporation | Flow control credit updates for virtual channels in the Advanced Switching (AS) architecture |
| US20060140122A1 (en) * | 2004-12-28 | 2006-06-29 | International Business Machines Corporation | Link retry per virtual channel |
| EP1847071A4 (en) | 2005-01-26 | 2010-10-20 | Internet Broadcasting Corp B V | MULTI-DIFFUSION IN LAYERS AND EXACT ATTRIBUTION OF BANDWIDTH AND PRIORIZATION OF PACKETS |
| US8223745B2 (en) * | 2005-04-22 | 2012-07-17 | Oracle America, Inc. | Adding packet routing information without ECRC recalculation |
| US20060277126A1 (en) * | 2005-06-06 | 2006-12-07 | Intel Corporation | Ring credit management |
| US7315456B2 (en) * | 2005-08-29 | 2008-01-01 | Hewlett-Packard Development Company, L.P. | Configurable IO subsystem |
| US20070076667A1 (en) * | 2005-10-04 | 2007-04-05 | Nokia Corporation | Apparatus, method and computer program product to provide Flow_ID management in MAC sub-layer for packet-optimized radio link layer |
| TWI290284B (en) * | 2005-10-13 | 2007-11-21 | Via Tech Inc | Method and electronic device of packet error detection on PCI express bus link |
| US7929577B2 (en) * | 2005-10-13 | 2011-04-19 | Via Technologies, Inc. | Method and apparatus for packet error detection |
| US7660917B2 (en) * | 2006-03-02 | 2010-02-09 | International Business Machines Corporation | System and method of implementing multiple internal virtual channels based on a single external virtual channel |
| US7949794B2 (en) | 2006-11-02 | 2011-05-24 | Intel Corporation | PCI express enhancements and extensions |
| US7849243B2 (en) * | 2008-01-23 | 2010-12-07 | Intel Corporation | Enabling flexibility of packet length in a communication protocol |
| US8199759B2 (en) * | 2009-05-29 | 2012-06-12 | Intel Corporation | Method and apparatus for enabling ID based streams over PCI express |
| US9667315B2 (en) | 2012-09-05 | 2017-05-30 | Landis+Gyr Technologies, Llc | Power distribution line communications with compensation for post modulation |
| US9311268B1 (en) * | 2012-10-25 | 2016-04-12 | Qlogic, Corporation | Method and system for communication with peripheral devices |
| US9524261B2 (en) * | 2012-12-21 | 2016-12-20 | Apple Inc. | Credit lookahead mechanism |
| US10394731B2 (en) | 2014-12-19 | 2019-08-27 | Amazon Technologies, Inc. | System on a chip comprising reconfigurable resources for multiple compute sub-systems |
| US10523585B2 (en) | 2014-12-19 | 2019-12-31 | Amazon Technologies, Inc. | System on a chip comprising multiple compute sub-systems |
| US11200192B2 (en) | 2015-02-13 | 2021-12-14 | Amazon Technologies. lac. | Multi-mode system on a chip |
| US9588921B2 (en) * | 2015-02-17 | 2017-03-07 | Amazon Technologies, Inc. | System on a chip comprising an I/O steering engine |
| US9306624B1 (en) | 2015-03-31 | 2016-04-05 | Landis+Gyr Technologies, Llc | Initialization of endpoint devices joining a power-line communication network |
| US9461707B1 (en) | 2015-05-21 | 2016-10-04 | Landis+Gyr Technologies, Llc | Power-line network with multi-scheme communication |
| US20170187579A1 (en) * | 2015-12-24 | 2017-06-29 | Eric R. Borch | Maximizing network fabric performance via fine-grained router link power management |
| CN106357560A (zh) * | 2016-09-26 | 2017-01-25 | 航天恒星科技有限公司 | 信道统计复用方法及装置 |
| KR102405773B1 (ko) * | 2017-09-27 | 2022-06-08 | 삼성전자주식회사 | Usb 타입 c 인터페이스를 이용한 멀티 디바이스 간의 통신 방법 및 이를 구현한 전자 장치 |
| CN116303150B (zh) * | 2023-05-25 | 2023-07-21 | 深圳市链科网络科技有限公司 | 一种基于虚拟usb的数据驱动方法及装置 |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5953338A (en) * | 1996-12-13 | 1999-09-14 | Northern Telecom Limited | Dynamic control processes and systems for asynchronous transfer mode networks |
| US6229803B1 (en) * | 1998-08-05 | 2001-05-08 | Sprint Communications Co. L.P. | Telecommunications provider agent |
| US6266345B1 (en) * | 1998-04-24 | 2001-07-24 | Xuan Zhon Ni | Method and apparatus for dynamic allocation of bandwidth to data with varying bit rates |
Family Cites Families (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5353382A (en) * | 1990-10-15 | 1994-10-04 | California Institute Of Technology | Programmable synapse for neural network applications |
| US5463629A (en) * | 1992-07-13 | 1995-10-31 | Ko; Cheng-Hsu | Dynamic channel allocation method and system for integrated services digital network |
| US5353282A (en) * | 1993-03-18 | 1994-10-04 | Northern Telecom Limited | Local area network embedded in the communication switch core |
| US5745837A (en) * | 1995-08-25 | 1998-04-28 | Terayon Corporation | Apparatus and method for digital data transmission over a CATV system using an ATM transport protocol and SCDMA |
| US6003062A (en) * | 1997-07-16 | 1999-12-14 | Fore Systems, Inc. | Iterative algorithm for performing max min fair allocation |
| DE19835668A1 (de) * | 1997-08-07 | 1999-02-25 | Matsushita Electric Ind Co Ltd | Übertragungsmedienverbindungsvorrichtung, steuernde Vorrichtung, gesteuerte Vorrichtung und Speichermedium |
| JP3075251B2 (ja) * | 1998-03-05 | 2000-08-14 | 日本電気株式会社 | 非同期転送モード交換網における仮想パス帯域分配システム |
| US6393506B1 (en) * | 1999-06-15 | 2002-05-21 | National Semiconductor Corporation | Virtual channel bus and system architecture |
| US6751214B1 (en) * | 2000-03-30 | 2004-06-15 | Azanda Network Devices, Inc. | Methods and apparatus for dynamically allocating bandwidth between ATM cells and packets |
| US6639919B2 (en) * | 2001-05-01 | 2003-10-28 | Adc Dsl Systems, Inc. | Bit-level control for dynamic bandwidth allocation |
-
2001
- 2001-09-30 US US09/968,620 patent/US6691192B2/en not_active Expired - Lifetime
-
2002
- 2002-09-27 EP EP02768920A patent/EP1433067B1/en not_active Expired - Lifetime
- 2002-09-27 CN CNB028193067A patent/CN100416528C/zh not_active Expired - Lifetime
- 2002-09-27 WO PCT/US2002/031003 patent/WO2003029995A1/en active IP Right Grant
- 2002-09-27 KR KR1020047004697A patent/KR100611268B1/ko active IP Right Grant
- 2002-09-27 DE DE60219047T patent/DE60219047T2/de not_active Expired - Lifetime
- 2002-09-27 AT AT02768920T patent/ATE357696T1/de not_active IP Right Cessation
-
2003
- 2003-09-03 US US10/655,523 patent/US6993611B2/en not_active Expired - Lifetime
-
2004
- 2004-08-06 HK HK04105865A patent/HK1063091A1/xx not_active IP Right Cessation
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5953338A (en) * | 1996-12-13 | 1999-09-14 | Northern Telecom Limited | Dynamic control processes and systems for asynchronous transfer mode networks |
| US6266345B1 (en) * | 1998-04-24 | 2001-07-24 | Xuan Zhon Ni | Method and apparatus for dynamic allocation of bandwidth to data with varying bit rates |
| US6229803B1 (en) * | 1998-08-05 | 2001-05-08 | Sprint Communications Co. L.P. | Telecommunications provider agent |
Also Published As
| Publication number | Publication date |
|---|---|
| DE60219047D1 (de) | 2007-05-03 |
| DE60219047T2 (de) | 2007-12-13 |
| US6993611B2 (en) | 2006-01-31 |
| KR100611268B1 (ko) | 2006-08-10 |
| US6691192B2 (en) | 2004-02-10 |
| CN1561490A (zh) | 2005-01-05 |
| EP1433067A1 (en) | 2004-06-30 |
| US20040044820A1 (en) | 2004-03-04 |
| EP1433067B1 (en) | 2007-03-21 |
| US20030115391A1 (en) | 2003-06-19 |
| KR20040037215A (ko) | 2004-05-04 |
| ATE357696T1 (de) | 2007-04-15 |
| HK1063091A1 (en) | 2004-12-10 |
| WO2003029995A1 (en) | 2003-04-10 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN100416528C (zh) | 增强型通用输入/输出体系结构及在其中建立虚拟信道的有关方法 | |
| CN100367254C (zh) | 用于将老式设备集成在egio体系结构中的方法和设备 | |
| CN100442257C (zh) | 提供同步信道的通用输入/输出装置和方法 | |
| CN101674158A (zh) | 增强型通用输入/输出体系结构中的差错转发及有关方法 | |
| CN100579108C (zh) | 一种远程密钥验证的方法和主机结构适配器 | |
| CN102984123B (zh) | 使用多个消息组的计算机系统中的代理之间的通信消息请求事务类型 | |
| CN101901205B (zh) | 在PCIExpress上启用基于ID的流的方法和装置 | |
| US6678773B2 (en) | Bus protocol independent method and structure for managing transaction priority, ordering and deadlocks in a multi-processing system | |
| JP4638216B2 (ja) | オンチップバス | |
| CN104536940B (zh) | 发送/接收具有扩展头部的分组的互连装置以及相关联的片上系统与计算机可读存储介质 | |
| CN1608255B (zh) | 使用包括扩展类型/扩展长度字段的分组头部的计算机系统中的代理之间的通信事务类型 | |
| CN103490852B (zh) | 用于处理与点到点数据链路有关的数据的方法和装置 | |
| KR101686360B1 (ko) | 다중슬롯 링크 계층 플릿에서의 제어 메시징 | |
| CN104823167B (zh) | 现场错误恢复 | |
| US7493426B2 (en) | Data communication method and apparatus utilizing programmable channels for allocation of buffer space and transaction control | |
| CN101681325B (zh) | 修改PCI Express封包摘要的设备、系统和方法 | |
| US20090113082A1 (en) | Device, System, and Method of Speculative Packet Transmission | |
| CN105793828A (zh) | Pci快速增强 | |
| US20080313240A1 (en) | Method for Creating Data Transfer Packets With Embedded Management Information | |
| CN107078850B (zh) | 边带奇偶校验处理 | |
| WO2000026763A1 (en) | Method and apparatus for routing and attribute information for a transaction between hubs in a computer system | |
| US20030070014A1 (en) | Data transfer in host expansion bridge | |
| TWI246651B (en) | An enhanced general input/output architecture and related methods for establishing virtual channels therein | |
| TWI240859B (en) | Error forwarding in an enhanced general input/output architecture and related methods | |
| JP2007265108A (ja) | バスブリッジ |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| C14 | Grant of patent or utility model | ||
| GR01 | Patent grant | ||
| CX01 | Expiry of patent term |
Granted publication date: 20080903 |
|
| CX01 | Expiry of patent term |