
What is Single Instruction, Multiple Data (SIMD)?
SIMD stands for Single Instruction, Multiple Data. This powerful approach allows a single CPU instruction to process multiple data points simultaneously. Imagine you're working with an image or two vectors. Normally, operations on these data points would be performed one at a time - a method known as scalar operation. However, with SIMD optimization, these operations can be vectorized, meaning multiple data points are processed in one go. SIMD architectures typically organize data into vectors or arrays, enabling synchronized execution and faster computational throughput.
SIMD techniques have evolved alongside advancements in computer architecture and instruction set extensions. Initial SIMD implementations emerged in the 1990s, and subsequent developments, such as Intel's Streaming SIMD Extensions (SSE) and Advanced Vector Extensions (AVX), expanded SIMD capabilities. These extensions introduced specialized SIMD instructions that significantly improved computational performance by enabling efficient execution of parallel operations.
How SIMD Facilitates Vectorization
SIMD (Single Instruction, Multiple Data) directly facilitates vectorization in computing:
-
Vectorization's Hardware Platform: SIMD provides the hardware capability for vectorization, which is the process of adapting algorithms to handle data in vectors (arrays) rather than processing single data points one at a time.
-
Parallel Data Processing Mechanism: SIMD's core functionality allows a single instruction to operate on multiple data points simultaneously, enabling the effective parallel processing that vectorization seeks to utilize.
-
Optimization through Parallelism: In high-performance computing, vectorization leverages SIMD to enhance computational speed, particularly for large datasets, by enabling parallel data processing.
Why is SIMD Optimization Effective?
The key benefit of SIMD optimization lies in its ability to significantly reduce the number of times the CPU needs to access memory. For instance, consider a scenario where, without SIMD, you would need to fetch and return data one piece at a time. This might involve, say, twelve memory accesses and twelve individual instructions. SIMD optimization slashes this requirement dramatically. By processing data in a columnar, batch format, the number of instructions can be reduced to as few as three. This not only speeds up execution but also enhances overall efficiency:
-
Enhanced Performance: SIMD provides substantial performance gains by exploiting data parallelism, executing multiple operations simultaneously, and leveraging processor capabilities more efficiently.
-
Accelerated Processing: SIMD accelerates computationally intensive tasks, such as multimedia processing, image and video processing, scientific simulations, and signal processing, by parallelizing computations.
-
Energy Efficiency: By executing multiple operations in parallel, SIMD reduces the number of instructions and processor cycles required, resulting in improved energy efficiency.
-
Optimized Memory Access: SIMD techniques optimize memory access by processing contiguous data elements, reducing memory latency and enhancing overall performance.
-
Simplified Programming: SIMD instruction sets offer high-level programming abstractions, making it easier for developers to utilize SIMD capabilities without extensive low-level optimizations.
Challenges in SIMD Implementation
-
Vectorization: Identifying and vectorizing code sections to leverage SIMD instructions efficiently can be a challenging task, requiring careful analysis and optimization.
-
Data Dependencies: Dependencies among data elements can hinder efficient SIMD execution. Handling dependencies and ensuring data coherence across SIMD lanes can be complex.
-
Memory Alignment: SIMD instructions often require aligned memory access. Ensuring proper memory alignment can be challenging, especially when dealing with irregular data structures or dynamic memory allocations.
-
Code Portability: SIMD implementations are architecture-specific, which can pose challenges when porting SIMD code across different platforms and instruction sets.
-
Load Imbalance: Unequal work distribution among SIMD lanes can result in load imbalance, affecting overall performance. Balancing workloads and data distribution is critical for optimal SIMD utilization.
How SIMD Works
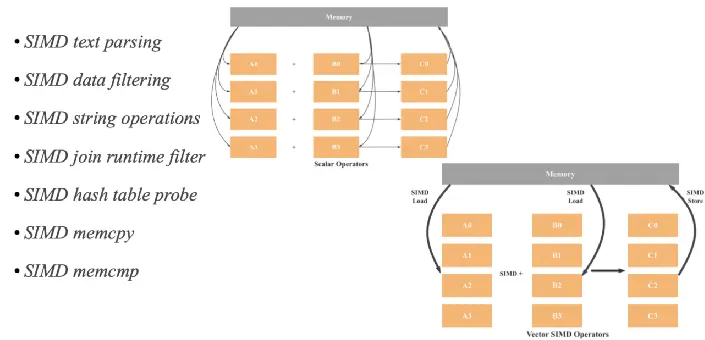
SIMD optimization works by allowing a single processor instruction to simultaneously process multiple data points. Here's a breakdown of how it operates:
-
Parallel Processing: In traditional CPU operations, instructions are executed on single data elements sequentially. In contrast, SIMD enables the execution of the same operation on multiple data elements at once.
-
Data Organization: Data is organized into vectors or arrays. A SIMD-enabled processor can load, process, and store these vectors efficiently.
-
Instruction Set Architecture (ISA): SIMD utilizes specialized instructions within the processor's instruction set. These instructions are designed to carry out operations on entire data vectors instead of individual elements.
-
Vectorized Operations: Common operations such as addition, subtraction, multiplication, and more are executed on all elements of a vector simultaneously. This parallelism dramatically speeds up processing times for tasks involving large datasets.
-
Reduced Memory Access: Since SIMD processes data in blocks, it reduces the number of times the processor needs to access memory, which is typically a slow operation. This results in a significant performance boost, especially in data-intensive tasks.
-
Efficient Use of Processor Resources: SIMD makes more efficient use of the processor's capabilities, as it can perform multiple operations in the time it would normally take to perform a single operation.
In essence, SIMD optimization capitalizes on the idea of doing more work in each processor cycle, leading to faster processing and more efficient use of computational resources, particularly for tasks that involve large arrays of data.
SIMD Optimization in StarRocks
StarRocks, a database system developed in C++, heavily optimizes for SIMD. This optimization allows for processing several data points in one go with a single CPU instruction, thus engaging memory less frequently. For instance, in operations like vectorized multiplication, SIMD reduces the number of memory accesses and instructions needed, significantly accelerating execution. SIMD optimization is applied in StarRocks for various operations, including text parsing, filtering, aggregations, joins, and more. The AVX2 instruction set, a SIMD CPU instruction set, is a prerequisite for StarRocks to leverage these vectorization capabilities effectively.

Join StarRocks Community on Slack
Connect on Slack.jpg)

